
Yohan Beschi
Developer, Cloud Architect and DevOps Advocate
From source code to Production - Traditional Applications Release Management

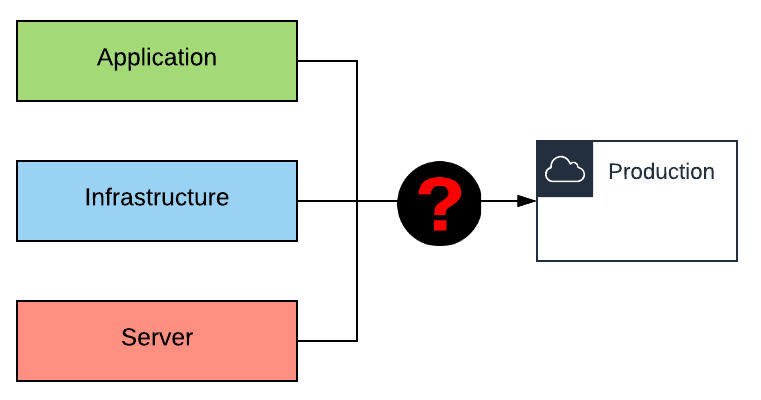
When moving to the Cloud from years of on-premise background we tend to apply what we know -and it is natural- using VPCs, Load Balancers, EC2s, etc. and at the same time we try to follow the AWS Well-Architected Framework and adopt DevOps practices.
Deploying a VPC with subnets, creating a Load Balancer, launching EC2 instances or provisioning them inside the user data is quite simple ; until we get to the point we have three main components: the Application source code, the Infrastructure as Code and the EC2 instances provisioning (with Ansible or other), and we need to find a way to bring all of them together in a CI/CD pipeline.
Table of Contents
- Organizing your code
- Application Source Code
- Infrastructure as Code
- EC2 provisioning
- Storing the configuration
- Security Patching
- CI/CD Pipelines
- Conclusion
We’ve already seen how to deploy CloudFormation templates using Ansible, create Golden AMIs and provision EC2 instances using Ansible. Now we want to push code to our application, infrastructure or OS repositories, and deploy everything from a development to a production environment with little to no user interaction.
And this is the purpose of a CI/CD pipeline (CI means Continuous Integration and CD can either mean Continuous Delivery or Continuous Deployment):
- Continuous Integration - Build and Test
- Continuous Delivery - Frequent shipping of code to a given environment via manual release
- Continuous Deployment - Automated release of code to a production environment
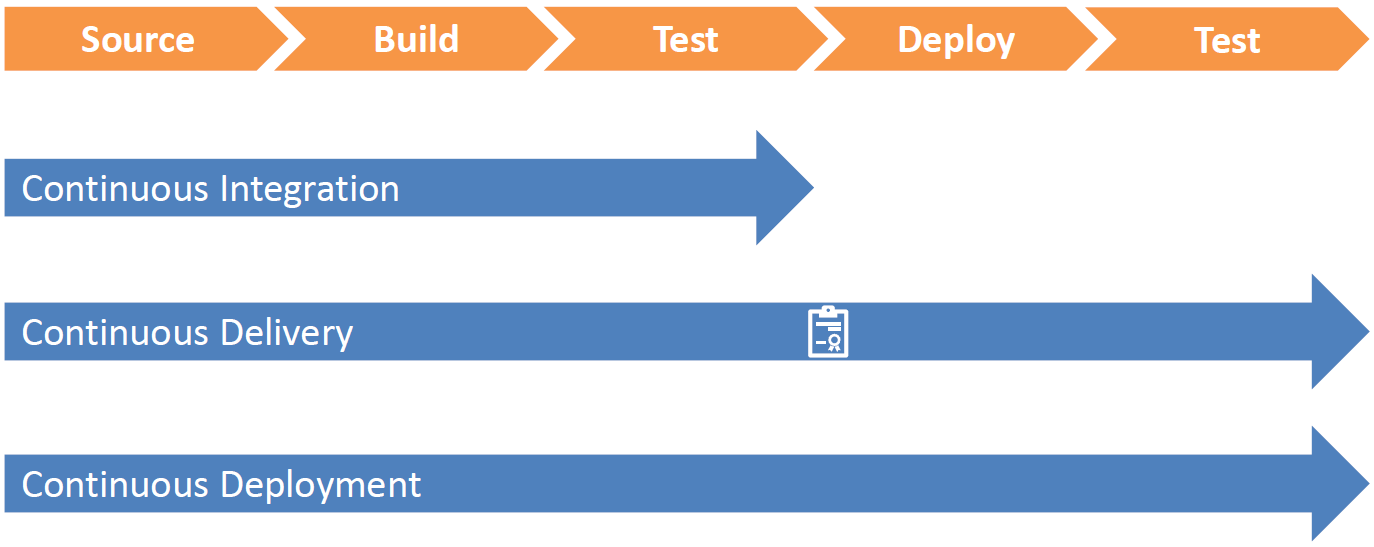
The most important rule to follow is that a single CI/CD pipeline must include all the environments (with optionally manual deployments) and the packages must be tested and built only once at the beginning of the pipeline (the same package must be deployed in each environment afterward).

Our application infrastructure can be quite simple (an ALB in front of an application server and a database):
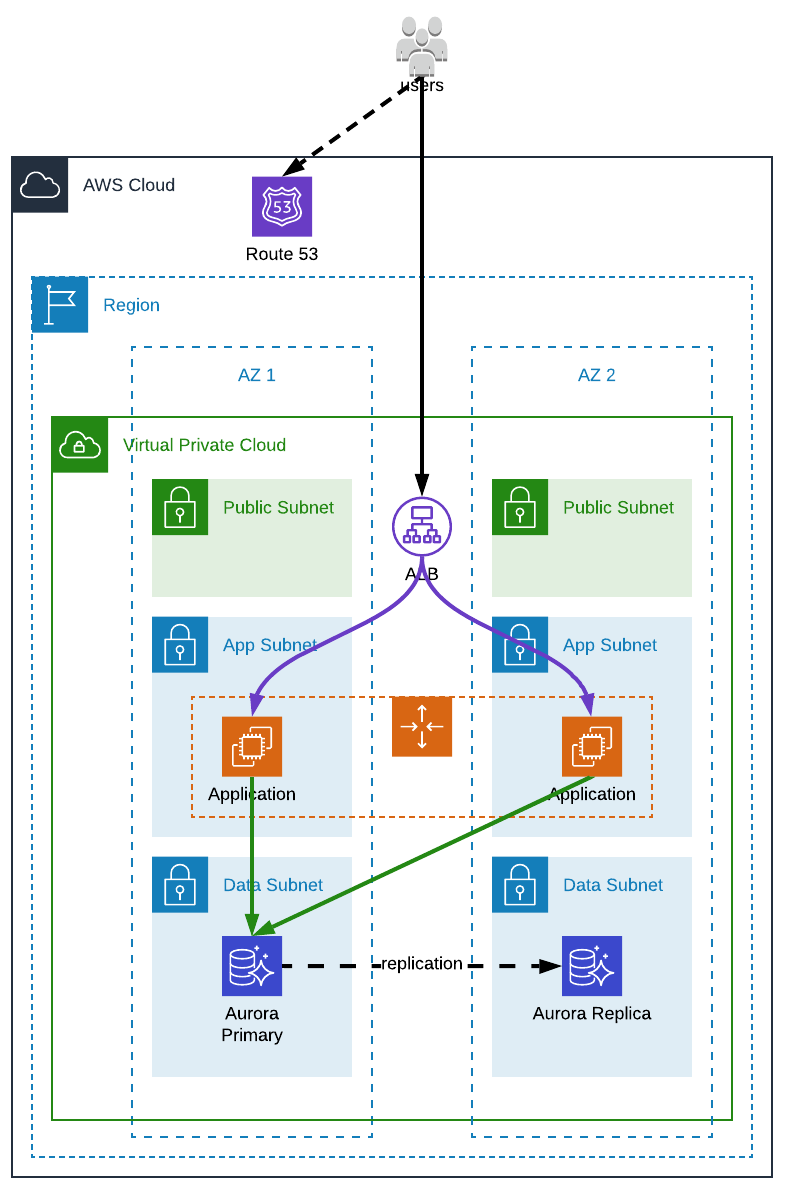
The infrastructure of every environment (development, production, etc.) being exactly the same, only the configuration is different (instances type, volumes size, AZs, endpoints, etc.).
Or we can have an infrastructure a little bit more complex, with a prime/central AWS account, some kind of a gateway from/to internet, into which we can have:
- a shared AWS CloudFront distribution used for all environments and have the same origin, a reverse proxy
- a AWS Transit Gateway to have a multi-accounts/VPCs private network (which is more powerful than a simple VPC peering)
- a Private Hosted Zone associated with the development and production VPCs to have a single hosted zone to manage all private DNS
- a central logging bucket used by all the AWS accounts
- a reverse proxy to forward the requests to the right environment
With a reverse proxy we could even:
- have our frontend stored in a S3 bucket (in each “environment” AWS account) and forward requests based on the hostname or the request path
- setup a maintenance page mechanism based on a flag stored in SSM Parameter store, which could “disable” an entire application at once
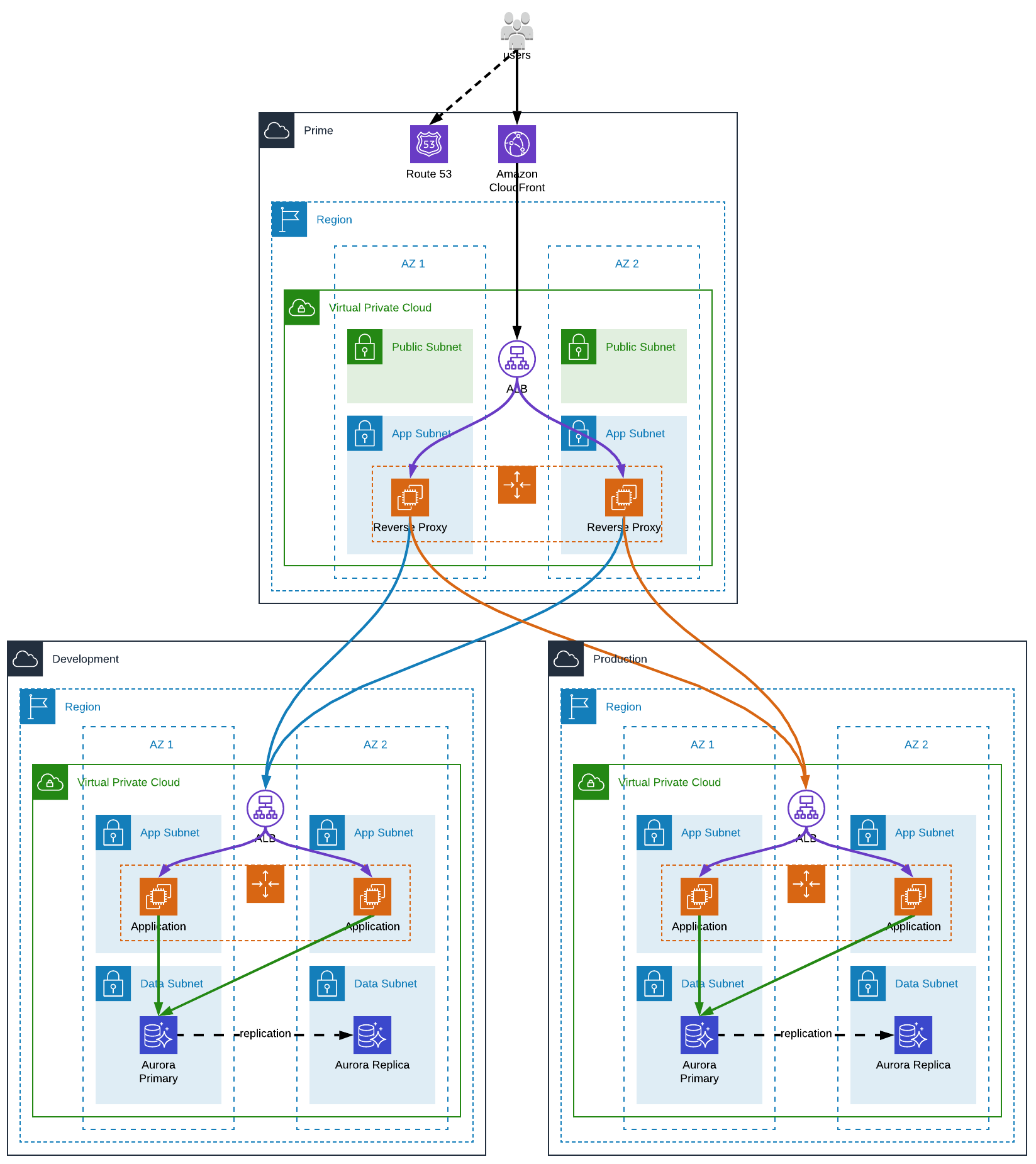
Of course, by setting up this kind of architecture you must have a pretty good reason as it increases the complexity drastically. As a rule of thumb, let’s say that if a cross-account architecture can be avoided, it should be.
Organizing your code
You have chosen one (or more) programming language(s), you have a pretty good idea of your infrastructure in the cloud and how you will architecture your application (layers, microservices, etc.). Now, you are facing a choice that could change everything, making your life easy or extremely hard, knowing that reconsidering your choice in the future will probably not be possible without a complete refactoring which will take time and cost a lot of money.
Organizing your code is essentially choosing the number of source repositories (git, Mercurial, etc.) needed to fulfill your requirements mainly focusing on your release management and code sharing. Unfortunately, there is no rule of thumb this time.
To define your requirements, you can start with the following questions:
- Will there be one person, one team or multiple teams working on the application?
- Do you want to share code or libraries across your company (or even publicly)?
- Will the application be monolithic or composed of multiple microservices?
- Will the configuration of the application change more often than the application itself?
- Will each developer
- have its own AWS account or
- work in the same AWS account?
- For each developer
- will all the AWS resources be duplicated or
- will there be centralized resources, like Amazon Route 53, Amazon Cognito or even a database?
Mono-repository
The easiest solution is to use a mono-repository with three main folders:
- frontend - html, css, JavaScript, etc.
- backend - it can be a monolithic application, microservices or even multiple applications
- infrastructure - AWS CloudFormation templates (or other depending on the IaC tool)
Then we can easily have a script to build, test and deploy everything every time. Of course, the easiest solution doesn’t always mean it is the best. For example, fixing a typo in an HTML file will result in the repackaging and redeployment of our backend for no reason. Concerning the infrastructure, our CI/CD pipeline will try to update it but with no change, nothing will happen and therefore the impact is very limited.
Multi-repositories
With that in mind we want to jump to the diametrically opposite model, with a source repository for each component:
- one for the frontend
- one for the mobile application(s), if any
- one for the infrastructure
- one for the application or for each microservice
- one for each shared library
And of course, we will face all new, and even worse, problems. Managing dozen of repositories, having:
- difficulties to know which version of a microservice is deployed
- difficulties to link the infrastructure and the code
- to store shared libraries into an artifacts repository and then updating the version of the dependencies everywhere they are needed, which does not simplify the development either
- to manage a dozen of CI/CD pipelines and/or source triggers
Smart mono-repository
Another alternative is to take the best features of each model, a mono-repository with a smart deployment. The mono-repository allows us to easily organize our code for the development lifecycle. The smart deployment offers the ability to share libraries, package our application, and update only required parts of our infrastructure.
Of course, we do not want to only know which folder has changed, we want to have a dependency tree between the folders to know what to do next (is it a library used by the application or shared by multiple microservices, a change to the frontend behind an Amazon CloudFront distribution which requires a cache invalidation, etc.).
Unfortunately, there is no tool today with such a feature, mainly because each project has very specific needs and every company has its own philosophy of how things should be done. But we can easily make one based on the git log command.
For example, using AngularJS repository, the command git log --name-status outputs the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
commit 83f084e5db95768dcee5302fa77924e1fb1f3239 (HEAD -> master, origin/master, origin/HEAD)
Author: George Kalpakas <kalpakas.g@gmail.com>
Date: Thu Aug 13 13:49:42 2020 +0300
chore(ci): avoid unnecessarily running `grunt prepareDeploy` in `deploy-docs` CI job
Previously, the `grunt prepareDeploy` command was run in both the
`prepare-deployment` and `deploy-docs` CI jobs. The reason was that not
all files affected by `grunt prepareDeploy` were persisted to the
workspace across jobs.
More specifically, the command would affect files in the `deploy/` and
`scripts/docs.angularjs.org-firebase/` directories and also create a
`firebase.json` file at the root directory, but only the `deploy/`
directory was [persisted to the workspace][1].
This commit avoids unnecessarily running the `grunt prepareDeploy`
command in the `deploy-docs` CI job by ensuring that all affected files
will be persisted to the workspace in the `prepare-deployment` CI job,
which always runs before `deploy-docs`.
[1]: https://github.com/angular/angular.js/blob/295213df953766625462/.circleci/config.yml#L265
Closes #17060
M .circleci/config.yml
commit 046887048af312ed786f0b52c6c5c97a33419fbf
Author: George Kalpakas <kalpakas.g@gmail.com>
Date: Mon Aug 3 02:04:30 2020 +0300
chore(ci): correctly deploy code and docs on version branches and tags
Previously, the generated build artifacts and docs were only deployed
for builds associated with the master branch. There was also a `latest`
branch mentioned in the config, but there is normally no such branch, so
this had no effect.
This commit fixes the rules so that deployments happen when necessary.
More specifically:
- The `deploy-code` job now runs for builds associated with:
- The master branch.
- The stable branch (i.e. the branch from which the version tagged as
`@latest` on npm is released).
- Tags of the form `v1.X.Y(-Z)`. (This also required configuring
CircleCI to run builds for git tags, which does not happen by
default.)
- The `deploy-docs` job now runs for builds associated with:
- The stable branch (i.e. the branch from which the version tagged as
`@latest` on npm is released).
The new rules for when deployments should take place are based on the
logic previously in [.travis.yml][1] and [scripts/travis/build.sh][2]
(from before we switched from Travis to CircleCI).
[1]: https://github.com/angular/angular.js/blob/974700af7c1/.travis.yml#L54-L103
[2]: https://github.com/angular/angular.js/blob/974700af7c1/scripts/travis/build.sh#L66-L101
M .circleci/config.yml
M .circleci/env.sh
commit f9b5cbfcf74bef5468d3da27d3db1c045d528a90
Author: George Kalpakas <kalpakas.g@gmail.com>
Date: Sun Aug 2 19:08:42 2020 +0300
chore(package.json): update docs app to use version 1.8 of AngularJS
As mentioned in `RELEASE.md`, now that the [CDN][1] has been updated
with the 1.8.0 version, it is safe to bump the value of the
`branchVersion` property in `package.json` to `^1.8.0`. This will cause
the docs app to use the latest version, namely 1.8.0.
[1]: https://ajax.googleapis.com/ajax/libs/angularjs/1.8.0/angular.js
M package.json
commit 0d14993d754e85df970ee25c9409c05b7043bbe7
Author: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Date: Thu Jul 30 13:59:48 2020 +0000
chore(deps): bump elliptic from 6.3.3 to 6.5.3
Bumps [elliptic](https://github.com/indutny/elliptic) from 6.3.3 to 6.5.3.
- [Release notes](https://github.com/indutny/elliptic/releases)
- [Commits](https://github.com/indutny/elliptic/compare/v6.3.3...v6.5.3)
Signed-off-by: dependabot[bot] <support@github.com>
Closes #17059
M yarn.lock
For each commit we have:
- the commit hash
- the author
- the date
- the commit message
- the files changed
AaddedMmodifiedDdeletedRxxrenamed
With the command git log --name-status 0d14993d754e85df970ee25c9409c05b7043bbe7..@ we can get the history from the commit 0d14993d... (excluded) to the HEAD (@ - the last commit of the current branch).
From this point, we have two issues to solve:
- We need to store the last commit hash to use it as a starting point the next time we want to deploy our application. This can easily be solved using SSM Parameter Store.
- We need a way to define a dependency tree between each component. This can be done using a JSON or YAML file, where we will have a folder path, the folder paths of its dependencies and the type of dependencies to know what to do next (is it a library which will become a Lambda Layer, an AWS Resource like an Amazon CloudFront distribution which requires an invalidation, etc.).
Writing such a tool can be time consuming at the beginning of a project. But, if designed and used correctly, it can become an invaluable asset and could even be shared across an organization.
Furthermore, it is worth mentioning that using multiple repositories does not avoid inadvertent commits. Working with a source repository requires strict and well-defined rules and workflows. Having master/production or master/development branches is mandatory and not all developers should have the permissions to push to these branches. Therefore, with a Pull/Merge Request model (and branch owners), which enforces code reviews, a single repository is protected as much as multiple repositories from mistakes or any harm.
But even with smart mono-repositories, not all problems can be solved. Shared resources in a central AWS account generally have a different lifecycle as the applications in each “environment” AWS account.
Application Source Code
Continuous Integration for an Application is a well-established process. Nevertheless, it doesn’t make things easier.
With a mono-repository and two branches: for releases and patches (respectively named master and production in the diagram), the development (release) branch will trigger a pipeline going through all the steps of the CI/CD pipeline, while the production (patch) branch is only present for bug fixes and the pipeline triggered by it will generally by-pass the deployment to some environment (i.e. development) to avoid overriding some changes from the development branch.
Of course, a production branch is optional depending on your release model. We could have a single branch and once a bug is fixed or a new feature added it will be shipped to production the same day at most (we won’t have to wait the next release in 2 or 3 weeks). This model is usually found in Continuous Deployment, where everything is automated, and no human interaction is required.
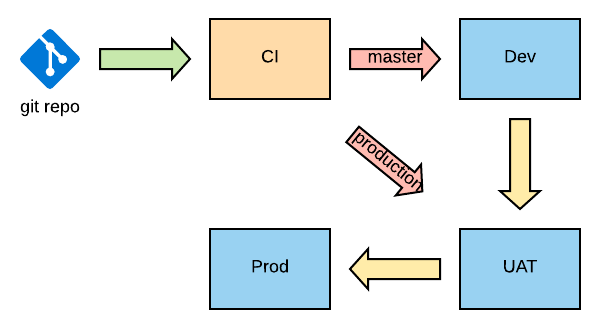
In the end the objective is to test and build an Application into a package that will be deployed in all the environments of the CI/CD Pipeline after a git push.
Infrastructure as Code
The application part is the easiest. We have one (or more) package(s) stored somewhere (AWS S3, AWS CodeArtifact, etc.), now we need to install it/them on server(s) in an infrastructure. Both (the infrastructure and the server configuration) can evolve as-well, and even if the lifecycles of these three components are usually linked it is not always the case (e.g. a shared resource between environments like a reverse proxy, an AWS S3 bucket, etc.).
No matter how many repositories we have and how they are split, we have at least three layers to have a fully functional application, that should be created/updated in the following order:
- AWS resources that should be initialized before anything else, like S3 buckets (e.g. artifacts bucket), CodeCommit Repositories, IAM Users and permissions (roles, groups, policies), CI/CD pipeline.
- Application/microservices packages
- Infrastructure AWS resources like Cognito, VPCs, Subnets, Databases, CloudFront distributions, EC2 instances, etc.
The first layer has resources that must be created manually (without a CI/CD pipeline but should still be created using Infrastructure as Code - with the exception of physical users). It goes without saying, but it still worth pointing out that we cannot push to a git repository, trigger a CI/CD pipeline, push artifacts to an S3 bucket, etc. if they do not exist.
And the same principles apply to the third layer. We cannot deploy an application if has not been built before.
Managing infrastructures with AWS CloudFormation has the main advantage that we can update a stack as many times as we want, if no change has been made, nothing will happen. We will only incur the time required by the service to see that nothing has changed.
Of course, when using a central account, things are a little different. But we will get back to it later.
EC2 provisioning
In a previous article, we have seen how easy it is to use Ansible Playbooks and Roles, and now it is time to dive into the more complex part. How to organize them to fit in a multi-environment infrastructure.
A general rule of thumb could be to have every middleware components in a dedicated git repository. With Roles designed in a generic way where specific configuration is controlled by variables passed to the Role or externally. Allowing us to create git tags completely independent from our application version and needs. But it is not always the appropriate choice, making everything more complicated to manage than they should be.
Let’s take an example composed of three applications:
- a reverse proxy, which needs:
- common tools on the OS (packages, agents, etc)
- the actual reverse proxy software
- the configuration of the reverse proxy
- a Java web application, which needs:
- common tools on the OS
- a JDK
- WildFly (Red Hat Web Application Server)
- a WAR of the application
- the configuration of the application (a DataSource, a MailSession, logging, etc.)
- a NodeJS application, which needs:
- common tools on the OS
- NodeJs
- a ZIP of the application
- the configuration of the application (endpoints to access the Java application, information concerning a Database, etc.)
From here on, the headaches will start. We first need to define the requirements by answering the following questions:
- Will there be one or more teams managing the applications?
- Will each application have its own server or will the three applications be installed on the same server?
- Will the reverse proxy be unique for an environment or shared between multiple environments?
- Will the applications be tightly linked? Or in other words, will we be able to deploy each application separately without being afraid of incompatibilities between versions?
- Will the configuration of one or more application change more often than the application itself?
And we can continue. But even with 5 questions we can have half a dozen of different structures for our project.
And once again we come back to how we organize our repositories.
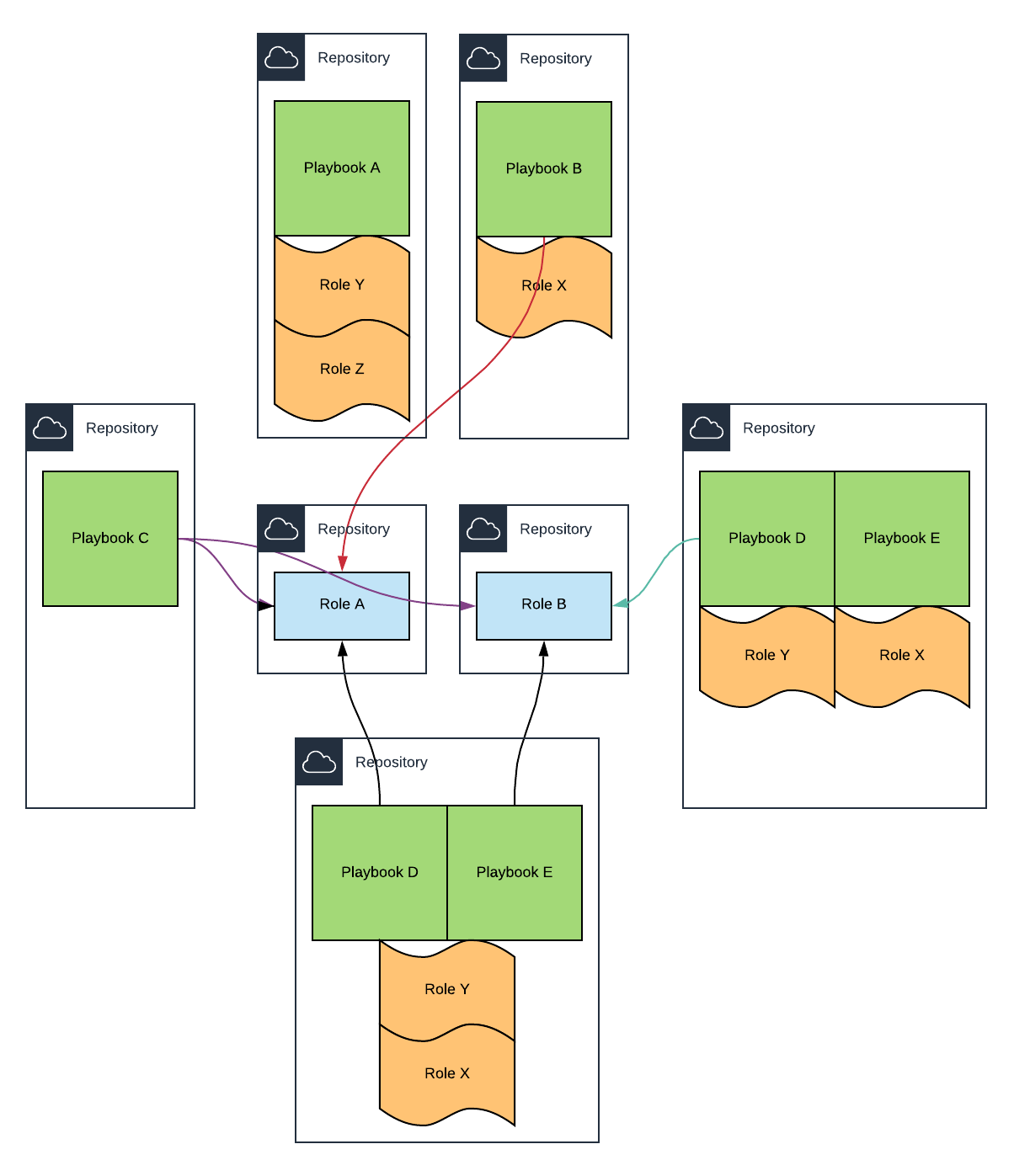
- Mono repository - Multiple playbooks with their roles in the same repository
- Split repositories - The complete opposite of the previous one, each role and playbook in its own repository
- Mixed repositories - Middleware roles in their own repository and, the Playbook and the Role of the application in another repository
- Application and Configuration Playbooks - Middleware roles in their own repository, the application playbook with its role and the application configuration in a playbook
- … Everything in between …
Storing the configuration
On top of the three main components which should be environment agnostic as much as possible we have a transversal one, the configuration of each component for each environment. Anything that can change between each environment can be considered as configuration: passwords, endpoints, AWS account IDs, AWS profiles, IP ranges, instance types, configuration files, etc.
The questions are where do we store those and how often do they change?
Storing passwords in a git repository is a bad idea, AWS Parameter Store or Secrets Manager are much more suitable for this task, and they can even be used to store simple configuration. But we need to pick one of them. Splitting the configuration between both services will make things harder to manage and to find when needed. When using AWS Parameter Store or Secrets Manager, each AWS account can hold its own configuration, that can be picked up by CloudFormation or Ansible when needed.
To setup passwords in Parameter Store or Secrets Manager we have two choices:
- store the scripts that will create/update the passwords on a secured vault, like an encrypted and versioned S3 Bucket to which only a handful of people have access.
- having a password generator/rotation mechanism with a lambda for example which will store the newly created passwords (this feature being present out of the box with AWS Secrets Manager)
But how to manage configuration files?
- The easiest solution is to avoid using pre-filled configuration files and to use templates instead, where the values come from Parameter Store or Secrets Manager.
- A more complex one is to use an Ansible playbook containing only the configuration of an application with a branch and/or tag for each environment, each branch/tag being completely independent of the others (rebases or merges making no sense in this situation).
Security Patching
Operating Systems (OS) go out of date pretty fast, and new security patches are available almost daily. As already mentioned in the article Keeping your system up-to-date with AWS Systems Manager, the best solution is to have an AMI Factory to regularly build new AMIs or when required. Unfortunately, it is not always possible to terminate an instance and launch a new one with the new AMI. Typically, stateful applications, like Databases should be terminated only as a last resort. Therefore, 1) we need to find out when there are security issues, 2) when there are fixed and 3) apply the patches.
Note: The following applies to Linux only!
Step 1 - Tools like Vuls can scan a system to check if installed softwares have vulnerabilities.
Step 2 can easily be solved by
- using AWS Inspector or
- using a tool like Vuls or
- (more complicated) running the package manager of our OS to list the packages that need to be updated and potentially run the result against the NIST database to only include packages that fix Common Vulnerabilities and Exposures (CVE) above a predetermined severity level
And finally, for the step 3 we can rely on SSM manager to execute a bash command on the server, which will install all security updates or only some. This operation can be automated to be executed at a predefined frequency or manual if we cannot/should not wait the next execution.
For some vulnerabilities, we have no choice, we need to install them in production as soon as a patch is available, and sometimes even rely on external trusted providers. But most of the time we should install them in each environment, following the CI/CD pipeline order to be sure that the fix does not break our application.
CI/CD Pipelines
So far we have covered a lot of topics, but we have only scratched the surface by pin pointing issues, without solving anything! Mainly due to the fact that so many parameters are to be taken into account we cannot have a one-fit-all solution. But following these rules can help a lot:
- We should use a cross-account architecture only when there is no other choice. The dependency between each account should be limited or even better each account should be considered as an independent entity with a completely different lifecycle. And we should not overlook the fact that a cross-account architecture requires cross-account permissions which are not easy to setup.
- Having a centralized IAM or logging account is a one-time setup, afterward everything can be considered as fine tuning. In this case a cross-account architecture is not an issue
- Having a centralized Resource, like a reverse proxy, introduces a single point of failure (not in the operational sense, but the DevOps sense). If we modify the version, configuration, etc. you need at least 2 infrastructures (production and non-production) to test our changes. And needless to say, in this case the account holding the reverse proxy and all the environment accounts are tightly linked.
- We should use AWS Secrets Manager or AWS Systems Manager Parameter Store instead of static configuration files and pull the values when needed
- We should build Configuration-less applicative AMI (everything up to the application without the configuration) as much as possible. This means that creating AMIs in part of the build process and we can use tools like Ansible in remote mode with Packer and a mono-repository without worrying of cloning repositories on the servers.
- We should use stateful applications only when there is no other choice.
- We should use multiple repositories only if we can afford to have dedicated teams for each repository (or a group of linked repositories), or at least work on them as if they were managed by different teams.
- Application:
- Libraries/shared component - when developing a library for an in-house application, it still should be considered as an independent product like any other library. And upgrading the version should be a manual action by the developers.
- Microservices - should be independent of each other with their own team and lifecycle. Therefore, APIs should be carefully designed to avoid going back and forth with changes and introducing too much noise in teams communication.
- Infrastructure
- The infrastructure can be split when using centralized accounts or to dissociate the initialization part (buckets, CI/CD, VPCs, Hosted Zones, Subnets, Databases, etc.) and the applicative part (Security Groups, EC2s, etc.) which could be integrated to the same repository as the application source code.
- Server
- Ansible roles should be environment/project agnostic (configuration-less), support most OSes (Amazon Linux, CentOS, RHEL and Ubuntu).
- Ansible playbooks should be environment agnostic to avoid having environment specific branches or different files for each environment. The configuration should be retrieved from AWS Secrets Manager or AWS SSM Parameter Store.
- Application:
Branches and tags
- Ansible Roles should be tagged (as in
git tag) and the tags should be referenced in the Ansible playbook to be used with ansible-galaxy. - Ansible Playbooks should be tagged as-well and the tag’s value could be stored in SSM Parameter Store and retrieved as a Parameter in the CloudFormation template with the type
AWS::SSM::Parameter::Value<String>. This Parameter will then be used in the user data to clone the right tag of the Ansible Playbook. - IaC and Application repositories should have at least two branches:
master/productionormaster/develop. The production branch (whatever its name) should only be used for bug fixes (patches).
CI/CD Pipeline example
That being said let’s see an example summarizing all of this. We are going to use a central AWS account for limited shared resources and each environment will have it is own AWS account. Furthermore, to not follow the easy road, we are going to use multiple repositories.
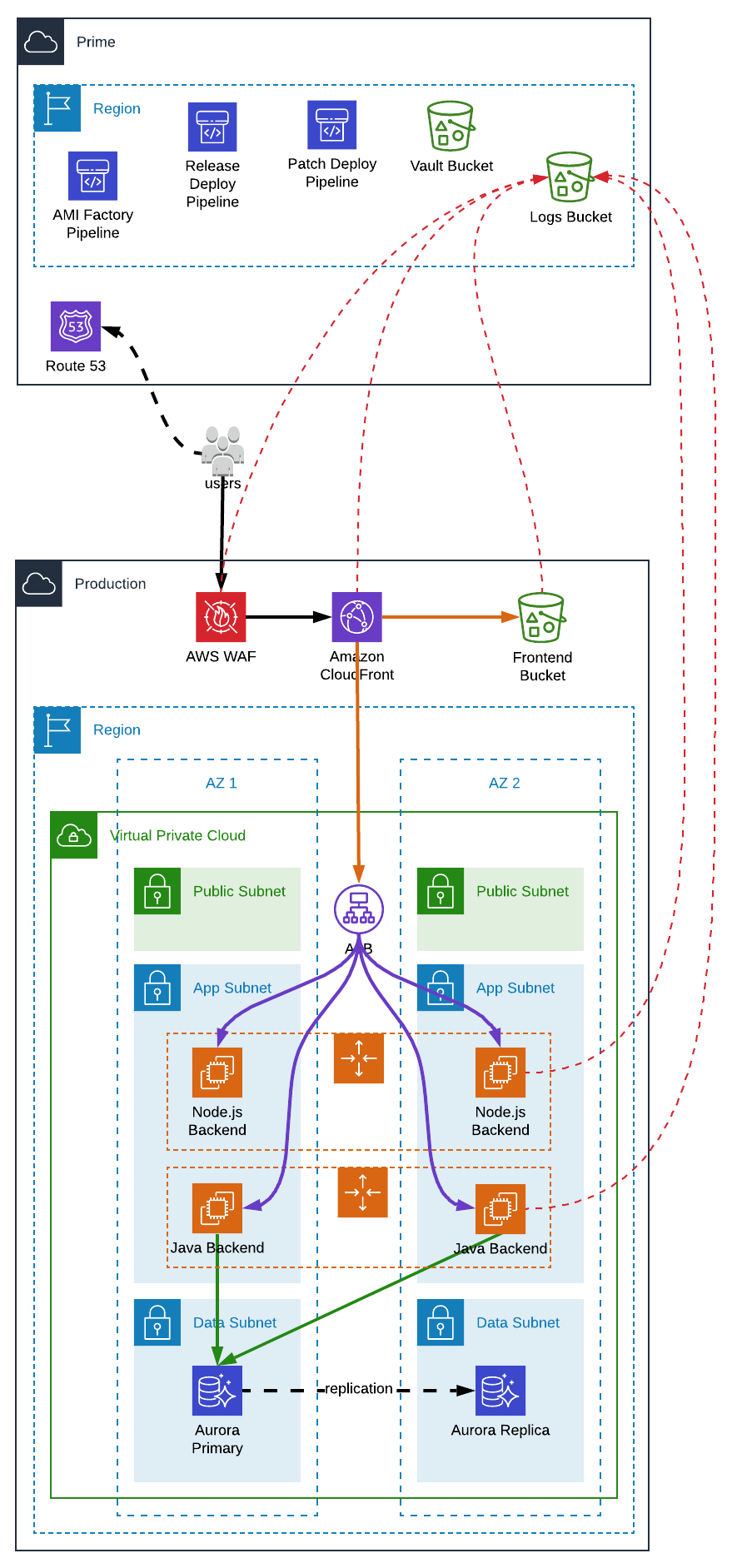
Notes:
- TLS certificates will be created manually
- The Public Hosted Zone will either be created automatically when buying a domain from AWS (or it could be created manually if we wanted to use another registrar)
- For infrastructure/provisioning purposes a Sandbox AWS account is mandatory in order to test everything manually before pushing our code. We do not have the luxury of application developers which can test their application locally on their computer.
AWS Initialization
The repository aws-initialization will contain CloudFormation templates for:
- All AWS accounts (each resource will be deployed in each AWS account - central and environments):
- An AWS Budget Alarm
- An AWS CloudTrail trail
- AWS GuardDuty (in all active AWS Regions)
- All CodeCommit repositories
- Central AWS account:
- A centralized S3 Logs Bucket
- An S3 Vault Bucket
- An AWS IAM Role to allow other AWS accounts to access CodeCommit and SSM Parameters stored in this account (i.e.
git-ansible-assumable-role) - An AWS CodePipeline for each AWS account to deploy the templates in this repository
- Environment AWS accounts:
- An AWS IAM Role to allow the central AWS account deployment CodePipeline to access resources (CloudFront, SSM Parameter Store, CloudFormation) in these accounts (i.e.
codepipeline-assumable-role)
- An AWS IAM Role to allow the central AWS account deployment CodePipeline to access resources (CloudFront, SSM Parameter Store, CloudFormation) in these accounts (i.e.
All the CloudFormation stacks defined in this repository will have to be deployed manually (not from a CI/CD Pipeline) at least the first time. But for all subsequent changes a push into this repository will trigger the Pipelines defined above using this repository as a Source in AWS CodePipeline. Of course, we will trigger all the pipelines every time even if we changed a CloudFormation template for the central account (or the opposite), but we want to keep things simple and redeploying a CloudFormation template that didn’t change has zero impact.
Central Infrastructure
The repository infrastructure-central will contain CloudFormation templates for the central AWS account which create the following resources:
- An Baseline AMI Factory CodePipeline
- A Public Hosted Zone (e.g.
myapp.com) - An AWS IAM Managed Policy to allow the central AWS account to assume the role
codepipeline-assumable-role - A “Release” deployment CodePipeline (all applications - Frontend, Java Backend, Node.js Backend - will be redeployed every time) linked to the
developbranch of the repositorymyapp(more on this later) as we want a single CI/CD pipeline covering all the environments - A “Patching” deployment CodePipeline linked to the
masterbranch of the repositorymyapp
All the CloudFormation stacks defined in this repository will have to be deploy manually (not from a CI/CD Pipeline). Furthermore, as the resources are unique (not different for each environment) using branches does not make any sense.
Baseline AMI factory
The repository baseline-ami-factory will contain:
- the Ansible Roles and Playbook to create a Baseline AMI with common tools and special OS configuration (e.g. setup of the Time zone)
- an AWS CodeBuild buildspec file
- a Packer configuration file
For more details see AMI Factory With AWS.
The CI/CD pipeline created in the previous step (Central Infrastructure) will be triggered by a push into this repository and at a scheduled frequency (e.g. every week) using an AWS CloudWatch Event Rule to have an AMI up-to-date.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
CloudwatchEventRole:
Type: AWS::IAM::Role
Properties:
RoleName: cloudwatch-event-ami-centos7-pipeline-role
Path: /
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Action: sts:AssumeRole
Effect: Allow
Principal:
Service: events.amazonaws.com
Policies:
- PolicyName: !Sub cloudwatch-event-ami-centos7-pipeline-role-policy
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action: codepipeline:StartPipelineExecution
Resource:
- !Sub arn:aws:codepipeline:${AWS::Region}:${AWS::accountId}:${Pipeline}
EventRuleCron:
Type: AWS::Events::Rule
Properties:
Name: ami-centos7-pipeline-cron-event-rule
Description: !Sub Execute factory pipeline at some frequency
State: ENABLED
ScheduleExpression: !Sub cron(${Scheduling})
Targets:
- Id: AmiFactoryPipelineSchedule-ami-centos7
Arn: !Sub arn:aws:codepipeline:${AWS::Region}:${AWS::accountId}:${Pipeline}
RoleArn: !GetAtt CloudwatchEventRole.Arn
Furthermore, the last step of the buildspec file will put the newly build AMI ID into SSM Parameter (e.g. with the key /myapp/ami/centos7/golden/id).
Monitoring Playbook
The repository ansible-playbook-monitoring will contain Ansible an Playbook and Role which will install all required tools for monitoring (e.g. DataDog agent) and configure them.
An AWS CloudWatch Event Rule will trigger a lambda which in turn will run an SSM Command every time a new EC2 instance is launched and at a scheduled frequency (e.g. every day at 2am GMT). For more details see Keeping your system up-to-date with AWS Systems Manager.
Applications provisioning
The repositories ansible-playbook-backend-nodejs and ansible-playbook-backend-java will contain an Ansible Playbook with its Roles which will install and configure each backend. All the configuration will be stored in SSM Parameter Store.
As part of the value stored in SSM Parameter Store will be secrets, we will use scripts (one for each environment - Python is a good fit for the task) to initialize and update the values. These scripts will then be uploaded to our vault bucket.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# utils.py
import boto3
class SsmParameterUpdater:
def __init__(self, profile_name, dry_run=False):
session = boto3.Session(profile_name=profile_name)
self._ssm_client = session.client('ssm')
self._dry_run = dry_run
def get_ssm_parameter(self, name: str):
try:
return self._ssm_client.get_parameter(
Name=name,
WithDecryption=True
)['Parameter']['Value']
except:
return None
def put_ssm_parameter(self, name: str, value: str):
if self.get_ssm_parameter(name) != value :
if not self._dry_run:
self._ssm_client.put_parameter(
Name=name,
Value=value,
Type='String',
Overwrite=True
)
print(f'[modified] {name}')
else:
print(f'DR - [modified] {name}')
elif not self._dry_run:
print(f'[no change] {name}')
else:
print(f'DR - [no change] {name}')
1
2
3
4
5
6
7
8
# myapp-dev.py
# ssm = SsmParameterUpdater('myapp-dev')
ssm = SsmParameterUpdater('myapp-dev', dry_run=True)
ssm.put_ssm_parameter('/myapp/database/masteruser', 'someuser')
ssm.put_ssm_parameter('/myapp/database/password', 'averycomplicatedpassword')
# [...]
Pushing the scripts to S3
1
2
aws s3 sync . s3://myapp-prime-vault/ssm-parameters \
--profile myapp-prime --exclude "*" --include "*.py"
Getting the scripts from S3
1
2
aws s3 sync s3://myapp-prime-vault/ssm-parameters . \
--profile myapp-prime --exclude "*" --include "*.py"
Applications - Code and Infrastructure
The repository myapp will contain
- The source code of the three applications
- CloudFormation templates for the “environment” AWS accounts which create the following resources (each resource will be deployed in each AWS account):
- An AWS IAM Managed Policy to allow EC2 instances to assume the role
git-ansible-assumable-role - A VPC with
- a Private Hosted Zone (
[env.]myapp.aws) - 3 subnets (
public,private-app,isolated-data) - an Egress Only Internet Gateway for (
private-app) to be able to access OS Package repositories (i.e.yumorapt) - three VPC endpoints (for S3, SSM and CodeCommit)
- a Private Hosted Zone (
- A AWS Cognito User Pool (used by the frontend with the Amplify library and both backends in the “old-school” way - the backends control the authorizations mechanisms)
- A Frontend S3 Bucket
- An Aurora MySQL database deployed in an
isolated-datasubnet with the following ALIASdatabase.[env.]myapp.aws - An
internet-facingApplication Load Balancer (ALB) which will be shared between both backends and will forward the requests to the right Target Group based on theHostheader:javaapi.[env.]myapp.awsnodeapi.[env.]myapp.aws
- Route53 ALIASes between both FQDNs (defined above) and the ALB endpoint
- A WAF
- A CloudFront distribution shared between the three applications with the following mapping to the origin (see. Protecting an AWS ALB behind an AWS CloudFront Distribution)
[env.]myapp.compointing the Frontend Bucket and using an Origin Access Identity[env.]myapp.com/javaapipointing tojavaapi.[env.]myapp.aws[env.]myapp.com/nodeapipointing tonodeapi.[env.]myapp.aws
- An AWS ALB Listener Rule
- An AWS ALB Target Group
- An AWS AutoScaling Group with Blue/Green deployment
- Multiple Security Groups
- An AWS IAM Managed Policy to allow EC2 instances to assume the role
Note: [env.] being development, test, acceptance, etc. or nothing for production.
CI/CD integration
We have now 7 repositories (crazy world):
aws-initializationinfrastructure-centralbaseline-ami-factoryansible-playbook-monitoringansible-playbook-backend-nodejsansible-playbook-backend-javamyapp
For the repositories aws-initialization, baseline-ami-factory and ansible-playbook-monitoring we have already seen they have their lifecycle with their own CI/CD pipeline or CloudWatch Event Rule or both.
On the other side, the infrastructure-central repository contains only CloudFormation stacks that we will be deployed manually. Therefore, before deploying anything, creating a change set to see what will be the changes is mandatory.
Now we will discuss about the 3 remaining repositories.
Applications provisioning
- These repositories will be tagged with the version of the application (as defined by the Semantic Version specification).
- The push into theses repositories will not trigger a CI/CD pipeline. Consequently, changes in these repositories for a specific version must be done before the deployment of a new version of the application. Even if there is no change, a tag corresponding to the current version of the application must be created. Fortunately, the creation of this tag can be automated as we will see below.
- If a bug is discovered in production the patch version (see. SemVer) must be incremented and a new tag must be created. If a bug is discovered in any of the other environments the name of the tag must stay the same and therefore must be overridden.
Applications - Code and Infrastructure
A push into the repository myapp on the branch develop or master will trigger the “Release” or “Patch” CI/CD pipeline created in the central AWS account. Each stage of the pipeline is fairly simple:
- Build
- Transpile TypeScript to JavaScript, use Webpack and Babel for the frontend
- Create ZIP files for our JavaScript applications (frontend and backend)
- Create a JAR for the Java application
- Upload the JAR and ZIP files to S3
- Execute some linting
- Pre-Test
- Unit Tests
- Integration Tests
- UI Tests
- End-to-end Tests
- OWASP 10 checks
- Dependencies Vulnerability check
- Deploy
- Deploy all CloudFormation Templates
- Upload the frontend files to the Frontend S3 Bucket
- Invalidate the CloudFront Distribution cache
- Post-Test
- Smoke Tests
- Synthetics
- Chaos Monkey Tests
The only issue is to pass the right parameters to both backend CloudFormation templates and the easiest is to use SSM parameter store and CloudFormation Parameters of type AWS::SSM::Parameter::Value<String>.
- The AMI ID (we may have to copy from
/myapp/ami/centos7/golden/idin the central account to/myapp/javabackend/ami/idand/myapp/nodebackend/ami/idin a previous step of the pipeline) - The current version
- The current time
The current version will be used to retrieve the artifact from S3 in the Ansible Playbook during the provisioning and to checkout the right tag of the Playbook (ansible-playbook-backend-java or ansible-playbook-backend-nodejs):
1
2
3
4
5
6
7
UserData:
Fn::Base64: !Sub |
[...]
git clone --branch ${SsmVersionKey} \
--single-branch \
codecommit::eu-west-1://git-ansible@ansible-playbook-javabackend \
/root/asbpb-backend
For more details see Provision EC2 instances using Ansible.
As already mentioned, if there was no change in the playbooks and we want to avoid any useless manual operation we can add a step to check if the current version has a tag with this name and if not we could create it. This will require to clone the repository first, then create the tag and finally push it, but with CodeBuild it is not an issue.
The current time is only here to force the deployment of the applications if the AMI ID or the version have not changed (it must be in the user data):
1
2
3
4
UserData:
Fn::Base64: !Sub |
#!/bin/bash
echo "Deploying version ${SsmVersionKey} - ${SsmDeployTimeKey}"
And we are finally done. As we can see, even with a simple application things are getting quite complex very fast.
Conclusion
This article is the perfect example of why people want Serverless architectures. Managing a complete infrastructure in an automated way is hard, time consuming, error prone and by having more to manage we lower the line of our responsibility in the AWS Shared Responsibility Model, which is never a good thing. Even when our application is deployed, we still have to think of security issues patching. And even with an airtight infrastructure, Murphy’s law still applies: “Anything that can go wrong will go wrong”. We can try to be prepared, have a fault tolerant system, with a very low RPO and RTO, chaos monkey testing, etc. but we can still be hit by the unexpected. And the only thing we can do about it is to reduce the gap between what we can do and what can happen.
Of course, between Lambdas and EC2s, we have alternatives like containers or AWS Elastic Beanstalk, which offer more control than Lambdas while moving part of the responsibility to AWS. But they do not simplify everything, they are not as versatile as EC2 instances and workarounds should be avoided while trying to overcome their limitations.