
Yohan Beschi
Developer, Cloud Architect and DevOps Advocate
Handling secrets with AWS Elastic BeanStalk

Every web application needs to use secrets (e.g. an API Key, a database password, etc.). Theses secrets must be stored in a secured vault like AWS Secrets Manager or AWS SSM Parameter Store. In the ideal case, the application should directly access the appropriate service (with the help of correctly configured Instance Profiles) to retrieve these secrets. But we do not always have the possibility or even the will to change the code of an application. Either because we do not manage the source code, or we want our application to be Cloud Provider agnostic.
In these situations, we only want to have access to environment variables with those secrets. With AWS Elastic BeanStalk we can easily define environment variables. Unfortunately, these variables are not secured. 1) they are not encrypted at rest and 2) they are visible in clear text in the AWS Console and in the response of some Actions of the Elastic BeanStalk API.
To overcome this extremely inconvenient issue we need to use some workarounds using Elastic BeanStalk Custom Resource and CloudFormation Custom Resource in combination or a Procfile.
We will start with the application and infrastructure described in the article Spring Boot in AWS Elastic Beanstalk with AWS CloudFormation.
But before going any further, it is important to remember that the following code in our main CloudFormation template would not solve the issue at all. CloudFormation would retrieve the value and this value would still be stored in clear text.
1
2
3
- Namespace: aws:elasticbeanstalk:application:environment
OptionName: DB_PASSWORD
Value: !Sub '{{resolve:secretsmanager:ProdDBSecret:SecretString:password}}'
Table of Contents
- Storing secrets in AWS SSM Parameter Store
- AWS CloudFormation Custom Resource
- AWS Elastic Beanstalk Custom Resource
- Procfile to the rescue
- Conclusion
All the source code presented in this article is available in a Github repository.
Other articles of the AWS Elastic BeanStalk series
- Spring Boot in AWS Elastic Beanstalk with AWS CloudFormation
- AWS Elastic Beanstalk Blue/Green deployment with Ansible
- Always deploying the latest AWS Elastic Beanstalk Solution Stack
Storing secrets in AWS SSM Parameter Store
First, we are going to add the secrets in AWS SSM Parameter Store. This is quite easy, but few things should be kept in mind.
Secrets should never be pushed in a VCS. But they should be tracked, and their creation be automated. This can be done using an encrypted dedicated AWS S3 Bucket and few scripts (Python is a good fit for the task) to initialize and update the values.
Let’s create a utility class which will handle the calls to SSM, a Dry Mode and update only what is necessary:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
import sys
import boto3
class SsmParameterUpdater:
def __init__(self, profile_name, region_name):
if len(sys.argv) == 2 and sys.argv[1] == '--nodryrun':
self._dry_run = False
print('==================')
print('Update Mode')
print('==================')
else:
self._dry_run = True
print('==================')
print('Dry Run Mode')
print('==================')
session = boto3.Session(profile_name=profile_name, region_name=region_name)
self._ssm_client = session.client('ssm')
def get_ssm_parameter(self, name: str):
try:
return self._ssm_client.get_parameter(Name=name, WithDecryption=True)['Parameter']
except:
return None
def put_ssm_parameter(self, name: str, value: str, value_type: str = 'SecureString'):
param = self.get_ssm_parameter(name)
if not param or param['Value'] != value or param['Type'] != value_type:
if not self._dry_run:
self._ssm_client.put_parameter(
Name=name,
Value=value,
Type=value_type,
Overwrite=True
)
print(f'[modified] {name}')
else:
print(f'DR - [modified] {name}')
elif not self._dry_run:
print(f'[no change] {name}')
else:
print(f'DR - [no change] {name}')
We can now use the class SsmParameterUpdater in a new .py file.
1
2
3
4
5
6
7
from ssm_utils import SsmParameterUpdater
ssm = SsmParameterUpdater('myapp-dev', 'us-east-1')
ssm.put_ssm_parameter('/myapp/database/password/1', 'xxxx')
ssm.put_ssm_parameter('/myapp/database/password/2', 'xxxx')
# [...]
By default, the parameters are of type SecureString. We can create regular String or StringList using an extra parameter:
1
ssm.put_ssm_parameter('/cicd/deployed/color', 'blue', value_type='String')
The script can either be executed in:
- Dry Mode:
python ssm-labs.py - Update Mode:
python ssm-labs.py --nodryrun.
If we have multiple environments, each one can have its own file.
We could even have a template with all the parameters that should be defined to create a new environment.
Once we are done, we need to upload this script to the Vault Bucket in order to version it and share it with other team members:
1
2
#!/bin/sh
aws s3 sync --profile myapp-dev . s3://myapp-vault/ssm-parameters --exclude "*" --include "ssm-*.py"
On the other side we need to be able to download the script from the Vault Bucket:
1
2
#!/bin/sh
aws s3 sync --profile myapp-dev s3://myapp-vault/ssm-parameters . --include "*.py"
These scripts should be pushed to a VCS along the application and infrastructure code. But we must have a .gitignore file with the following entry ssm-*.py.
AWS CloudFormation Custom Resource
AWS CloudFormation Custom Resources are AWS Lambdas executed following CloudFormation stacks lifecycle (create, update and delete). One important point to remember is that the lambdas are re-executed (after creation) only if at least one of their parameters has changed (the lambdas will not be executed every time the stack is updated).
We need a very simple Lambda to retrieve values from SSM Parameter Store and return them in the Custom Resource response, everything else is part of a Custom Resource boiler plate code (backend.cfn.yml):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import json
import boto3
ACCEPT_PATHS = [
'/myapp/database/'
]
def accept_key(key):
for v in ACCEPT_PATHS:
if key.startswith(v):
return True
return False
def get_all_parameters():
ssm_client = boto3.client('ssm')
next_token = ' '
ssm_params = {}
while next_token is not None:
response = ssm_client.get_parameters_by_path(
Path='/',
Recursive=True,
WithDecryption=True,
NextToken=next_token
)
for param in response.get('Parameters'):
if accept_key(param['Name']):
ssm_params[param['Name']] = param['Value']
next_token = response.get('NextToken', None)
print(ssm_params.keys())
return ssm_params
It would be nice to be able to retrieve all the parameters from SSM Parameter Store and make them available to our application. But aside security concerns, we need to keep in mind that there is a maximum amount of data that a custom resource can return which is 4096 bytes. And therefore, limiting the amount of data returned is the constant ACCEPT_PATHS unique purpose.
This Lambda being quite short, it can be directly included in a CloudFormation template.
Concerning the Lambda IAM execution role, we only need the usual permissions to write into AWS CloudWatch, and the permission ssm:GetParametersByPath to retrieve values from SSM Parameter Store.
Now all the preparation work is done. We can move on to next step, using the Custom Resource Response from our AWS Elastic BeanStalk .ebextensions folder present in our bundle.
AWS Elastic Beanstalk Custom Resource
With AWS Elastic Beanstalk Custom Resource we can use a subset of AWS CloudFormation.
In a configuration file we can easily create our Custom Resource. Unfortunately, as we can only use a CloudFormation subset, we cannot use all Intrinsic functions.
1
2
3
4
5
6
7
8
9
10
11
ParameterStoreCustomResource:
Type: Custom::ParameterStore
Properties:
ServiceToken:
Fn::Join:
- ''
- - 'arn:aws:lambda:'
- Ref: AWS::Region
- ':'
- Ref: AWS::AccountId
- ':function:ssm-parameters-loader'
Now that we have our Custom Resource, we need to use its response to set environment variables with option_settings. To do so is quite easy, but the syntax, with the use of single quotes, double quotes and back ticks, is quite confusing and can be error prone:
1
2
3
option_settings:
aws:elasticbeanstalk:application:environment:
DATABASE_PASSWORD_1: '`{ "Fn::GetAtt": [ "ParameterStoreCustomResource", "/eb-secrets/database/password/1" ] }`'
Retrieving the value from our Code
To retrieve the environment variable DATABASE_PASSWORD_1 value, we will create a simple controller:
1
2
3
4
5
6
7
8
9
10
11
12
13
@RestController
@RequestMapping("/v1")
public class HelloController {
@Value("${DATABASE_PASSWORD_1}")
private String databasePassword1;
@RequestMapping(path = "/hello", method = RequestMethod.GET)
public Response health() {
return new Response(200, "OK - " + databasePassword1);
}
}
Now if we deploy everything and execute:
1
curl -i https://example.com/api/v1/hello
We are getting the following response:
1
2
3
4
5
6
HTTP/2 200
date: Sat, 13 Feb 2021 13:25:17 GMT
content-type: application/json
server: nginx
{"status":200,"message":"OK - 8gHA^u59L8y@wj-#3VwSpx*&&fJ+4Tgx"}
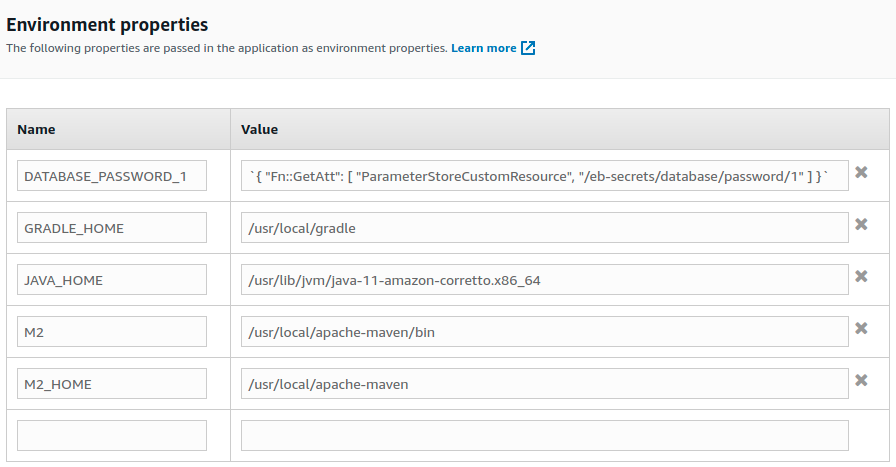
And in the AWS console our password database is not displayed.
A miracle solution?
We have now exactly what we wanted, with something that seems to be a smart idea. Or is it? The harsh reality is that we only moved the problem and broke few things along the way. With Elastic BeanStalk it is quite easy to become short sighted to fix a problem without thinking of all the ramifications even with small changes.
First, AWS does not disclose how secured are Custom Resources. We know that Custom Resources can only be executed by the CloudFormation service, but we have no idea of the encryption at rest and in transit.
Second, with immutable deployments (managed updates are immutable and as mentioned in the previous article any update type other than Immutable should be considered an extremely bad practice) we cannot update our Elastic BeanStalk environment anymore. Either with manual or managed updates, we will get the following error message:
CustomResource attribute error: Vendor response doesn’t contain
\/eb-secrets\/database\/password\/1key in object […] in S3 bucket cloudformation-custom-resource-storage-useast1
Third, any user that can login to the server, even without root privileges, can retrieve all the environment variables.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
$ aws ssm start-session --region us-east-1 --profile spikeseed-labs --target i-0e04206e669de980c
Starting session with SessionId: Yohan.Beschi@arhs-spikeseed.com-020fdc8a4e83df8f2
sh-4.2$ whoami
ssm-user
sh-4.2$ id ssm-user
uid=1002(ssm-user) gid=1002(ssm-user) groups=1002(ssm-user)
sh-4.2$ ls -l /opt/elasticbeanstalk/bin/get-config
-rwxr-xr-x 1 root root 11017206 Jan 22 19:50 /opt/elasticbeanstalk/bin/get-config
sh-4.2$ /opt/elasticbeanstalk/bin/get-config --output YAML environment
DATABASE_PASSWORD_1: 8gHA^u59L8y@wj-#3VwSpx*&&fJ+4Tgx
GRADLE_HOME: /usr/local/gradle
JAVA_HOME: /usr/lib/jvm/java-11-amazon-corretto.x86_64
M2: /usr/local/apache-maven/bin
M2_HOME: /usr/local/apache-maven
So where does this leave us?
Procfile to the rescue
As a matter of fact, the only solution to solve all the previous issues is platform specific. With the Java SE platform we can leverage the Procfile that we used in the previous article to launch the JVM with some options.
But as Procfiles do not support environment variable, this time our Procfile will execute a bash script:
1
web: ./start_app.sh
The file start_app.sh have to be at the root of the bundle:
1
2
3
4
5
6
7
8
#!/bin/bash
AWS_REGION=$(curl --silent http://169.254.169.254/latest/dynamic/instance-identity/document | jq -r .region)
export DATABASE_PASSWORD_1=$(aws ssm get-parameter \
--name /eb-secrets/database/password/1 \
--with-decryption --output text \
--query Parameter.Value --region $AWS_REGION)
exec java -jar -Xms2g -Xmx2g eb-secrets.jar --logging.config=logback.xml
As describe in this gist Starting an app with a shell script in Elastic Beanstalk:
When stopping/restarting the application, Beanstalk will send kill signals to the process specified to in the
Procfile. However, when we launch the application with a shell script, our app is spawned as a child process. The original script process now receives the kill signals, but our app never hears those signals and keeps running.
Prefixing the command withexecmakes it so our app will take over the original process of the script, including PID, environment, etc. When this happens, OUR app will receive the kill signals.
The last step is to make our script executable by adding a new configuration file in the .ebextensions folder:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
container_commands:
01_config_start_script:
command: /home/ec2-user/config-startscript.sh
files:
"/home/ec2-user/config-startscript.sh":
mode: "000755"
owner: root
group: root
content: |
#!/bin/bash
EB_APP_STAGING_DIR=$(/opt/elasticbeanstalk/bin/get-config platformconfig -k AppStagingDir)
chmod +x $EB_APP_STAGING_DIR/start_app.sh
If we redeploy everything (we first need to terminate the previous Elastic BeanStalk environment and remove the following configuration ParameterStoreCustomResource and options) and execute a curl command, we end up with the exactly the same result as before, but this time we will be able to redeploy the application without getting the previous error.
1
2
3
4
5
6
7
$ curl -i https://ybe.labs.spikeseed.cloud/api/v1/hello
HTTP/2 200
date: Sun, 14 Feb 2021 16:06:30 GMT
content-type: application/json
server: nginx
{"status":200,"message":"OK - 8gHA^u59L8y@wj-#3VwSpx*&&fJ+4Tgx"}
As already mentioned, this solution will only work with Elastic BeanStalk platforms using a Procfile, like Go, Java SE, Python or Ruby. With PHP for example, the way to have something similar will be to use a .env file.
Conclusion
Again, with AWS Elastic BeanStalk nothing is easy. Managed updates do not come for free; we have to work very hard to get them and unfortunately AWS Support Team will not always give you bullet proof and easy to use solutions.
In the next article, we will see how to setup a Blue/Green deployment pipeline to overcome yet another limitation with Immutable updates, changing the application and the configuration in a single deployment.