
Yohan Beschi
Developer, Cloud Architect and DevOps Advocate
AWS Lambda and Java

AWS Lambda is a cornerstone service. For AWS CloudFormation Custom Resources, CRON Tasks with AWS CloudWatch Events, Notifications Handlers, Serverless Applications and more, AWS Lambda is a particularly handy tool.
But Java has never been a language of choice for AWS Lambda. And for good reasons:
- Even for a simple application returning only a Hello World message, the cold start is twice as long as the same application in NodeJS or Python
- Deploying a Java Lambda requires a little work
- Java packages are quite heavy
- Integration Testing is far from being easy when using the AWS SDK
- A quick change for testing in the AWS Console is not possible
But the reality in not so dire. We love Java anyway; we always find ways to make it work.
Table of Contents
- Cold Start
- Minimal Lambda
- Packaging
- Deploying
- Event
- Logging
- Using the AWS SDK for Java 2.x
- AWS Lambda PowerTools
- Testing
- Conclusion
All the source code presented in this article is available in a Github repository.
Note: To deploy the Lambdas we are using AWS CodePipeline and AWS CodeBuild with an external buildspec.yml. The specifics will not be explained in this article.
Cold Start
As we have seen in a previous article, with GraalVM and frameworks like Quarkus, Java applications can be compiled natively and therefore, the cold start time can be considerably improved. Unfortunately, we cannot use any library and hope that it will be magically natively compiled. When we need a unsupported library by the framework we have to create an extension, some kind of wrapper that will help the compiler in its task. This is a daunting task and we cannot even be sure that it will work at the end.
Another way to mitigate the bad cold start time is to use provisioned concurrency (primarily for Serverless Applications). But except by over provisioning and therefore, increasing our bill, provisioned concurrency will not solve the cold start problem altogether.
And as already mentioned, we should not lose sight of the fact that AWS Lambda is not only used behind an AWS API Gateway and in these cases, we rarely need a lighting fast cold start.
Minimal Lambda
Let’s see how to create a simple Lambda in Java using Corretto 11 Runtime. As any Lambda, we need an handler method with two parameters (event and context). event can be of any type (e.g. java.lang.Object) but context must be of type com.amazonaws.services.lambda.runtime.Context which is available in the library aws-lambda-java-core.
When Lambda runs your function, it passes a context object to the handler. This object provides methods and properties that provide information about the invocation, function, and execution environment. - AWS Lambda context object in Java
We will add the dependency to our pom.xml.
1
2
3
4
5
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-lambda-java-core</artifactId>
<version>1.2.1<version>
</dependency>
Then we can create a simple class:
1
2
3
4
5
6
7
8
import com.amazonaws.services.lambda.runtime.Context;
import java.util.Map;
public class Handler {
public Object handleRequest(Object event, Context context) {
return "Hello World";
}
}
Before deploying this lambda, we first need to package everything.
Packaging
Anyone who already built packages for Python knows the pain of creating a simple ZIP file with all the dependencies, sometimes containing native libraries like psycopg2. But with Java if our code compiles locally we are pretty sure it will run in AWS Lambda.
With wonderful tools like Maven or Gradle, we can easily create Java packages with all their dependencies without having to worry on the OS used to create these packages. And once this configuration is done, we can place it in a parent pom and reuse it quite easily for any new lambda.
Using Maven we can display our dependency tree: mvn dependency:tree -Dverbose. With our simple example we have the following output:
1
2
3
[INFO] --- maven-dependency-plugin:2.8:tree (default-cli) @ java-helloworld ---
[INFO] cloud.spikeseed:java-helloworld:jar:1.0.0-SNAPSHOT
[INFO] \- com.amazonaws:aws-lambda-java-core:jar:1.2.1:compile
In the documentation, AWS uses the maven-shade-plugin to package the lambdas. The idea is to take our code and the content of all our dependencies to create a single JAR. Needless to say, this technic can have some nasty side effects (like overwriting files) and we should avoid using it.
A better solution is to create a ZIP file with the maven-assembly-plugin.
In our pom.xml we configure the plugin:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<executions>
<execution>
<id>zip-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
<configuration>
<finalName>${project.name}</finalName>
<appendAssemblyId>false</appendAssemblyId>
<descriptors>
<descriptor>src/main/assembly/package.xml</descriptor>
</descriptors>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<addDefaultImplementationEntries>true</addDefaultImplementationEntries>
<addDefaultSpecificationEntries>true</addDefaultSpecificationEntries>
</manifest>
</archive>
<attach>false</attach>
</configuration>
</execution>
</executions>
</plugin>
And in another XML file what the ZIP file should contain:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
<?xml version="1.0" encoding="UTF-8"?>
<assembly [...]>
<id>aws-lambda-package</id>
<formats>
<format>zip</format>
</formats>
<includeBaseDirectory>false</includeBaseDirectory>
<fileSets>
<fileSet>
<directory>${project.build.directory}${file.separator}classes</directory>
<outputDirectory />
</fileSet>
</fileSets>
<dependencySets>
<dependencySet>
<useProjectArtifact>false</useProjectArtifact>
<outputDirectory>lib</outputDirectory>
</dependencySet>
</dependencySets>
</assembly>
Finally, we build the ZIP file using the following command: mvn package.
We can then see the content of our newly created ZIP file: vi target/java-helloworld.zip.
1
2
3
4
5
cloud/
cloud/spikeseed/
lib/
cloud/spikeseed/Handler.class
lib/aws-lambda-java-core-1.2.1.jar
Deploying
To deploy our Lambda, we can use any tool we want: AWS CLI, AWS CDK, AWS SAM, SAM template with CloudFormation, AWS CloudFormation, Terraform, etc.
To keep things simple, we are going to use an AWS SAM template deployed with CloudFormation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
AWSTemplateFormatVersion: 2010-09-09
Transform: AWS::Serverless-2016-10-31
Resources:
HelloworldCorretto:
Type: AWS::Serverless::Function
Properties:
FunctionName: awslambdajava-helloworld
Handler: cloud.spikeseed.Handler::handleRequest
Runtime: java11
CodeUri: ../../lambdas/helloworld/target/java-helloworld.zip
MemorySize: 256
Timeout: 15
We can then execute two commands to deploy our lambda:
1
2
3
4
5
6
7
8
aws cloudformation package \
--template-file helloworld.cfn.yml \
--s3-bucket my-bucket \
--output-template-file helloworld.out.yml
aws cloudformation deploy \
--template-file helloworld.out.yml \
--stack-name l-use1-lambdajava-helloworld \
--capabilities CAPABILITY_NAMED_IAM
Once our Lambda is deployed, we can invoke it with the AWS CLI:
1
2
3
4
5
6
7
aws lambda invoke \
--profile spikeseed-labs \
--region us-east-1 \
--no-cli-pager \
--cli-binary-format raw-in-base64-out \
--function-name awslambdajava-helloworld \
/tmp/response.json
This will print the result of execution:
1
2
3
4
{
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}
To see what the function has returned we need to look at the response.json file:
1
2
$ cat /tmp/response.json
"Hello World"
We can even see the logs:
1
2
3
4
5
aws logs tail \
/aws/lambda/awslambdajava-helloworld \
--profile spikeseed-labs \
--region us-east-1 \
--no-cli-pager
The last line is the most interesting (formatted for easy reading):
1
2
3
4
5
Duration: 194.90 ms
Billed Duration: 195 ms
Memory Size: 256 MB
Max Memory Used: 90 MB
Init Duration: 382.95 ms
The cold start (Init Duration) is about 400 ms and the Lambda has been executed in 200 ms. Which bring the total invocation time to 600 ms.
Event
When a Lambda is invoked a payload can be used. Every AWS Service has its own payload format, but it is always a JSON object, translated into a Map<String, String> in Java.
This can be proven with a little modification of our code:
1
2
3
public Object handleRequest(Object event, Context context) {
return "Hello World - " + event.getClass();
}
By invoking the lambda with the command used previously we get the following response:
1
"Hello World - class java.util.LinkedHashMap"
Every AWS Service invoke a Lambda with a JSON payload, but we can invoke Lambdas manually as-well.
Let’s create a new Lambda which echoes the payload.
1
2
3
4
5
6
7
public class Handler {
private static final Gson gson = new GsonBuilder().setPrettyPrinting().create();
public String handleRequest(Object event, Context context) {
return gson.toJson(event);
}
}
To return the payload as a JSON string we are using a new library, Gson.
1
2
3
4
5
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.6</version>
</dependency>
Now we use again the same command with a new parameter: --payload '{"message":"Hello World From Payload"}'.
1
2
3
4
5
6
7
8
aws lambda invoke \
--profile spikeseed-labs \
--region us-east-1 \
--no-cli-pager \
--cli-binary-format raw-in-base64-out \
--function-name awslambdajava-echo \
--payload '{"message":"Hello World From Payload"}' \
/tmp/response.json
The content of the file response.json is as follow:
1
"{\n \"message\": \"Hello World From Payload\"\n}"
To avoid typing JSON in the command line or if the payload is too big we can use a file:--payload file://payload.json.
We can invoke a Lambda with a JSON object and retrieve its content in our code using a Map. But it is not how we do things in Java. We use Java to have Strong Typing, we do not want string literals to retrieve values in our objects. To do so, we need a new library, aws-lambda-java-events.
Let’s see how to use it with a new example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;
import com.amazonaws.services.lambda.runtime.events.APIGatewayV2HTTPEvent;
import com.amazonaws.services.lambda.runtime.events.APIGatewayV2HTTPResponse;
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import java.util.Map;
public class Handler implements RequestHandler<APIGatewayV2HTTPEvent, APIGatewayV2HTTPResponse> {
private static final Gson GSON = new GsonBuilder().setPrettyPrinting().create();
@Override
public APIGatewayV2HTTPResponse handleRequest(APIGatewayV2HTTPEvent event, Context context) {
var body = Map.of("status", 200, "message", "ok");
return APIGatewayV2HTTPResponse.builder()
.withStatusCode(200)
.withHeaders(Map.of("Content-Type", "application/json"))
.withBody(GSON.toJson(body))
.build();
}
}
With the aws-lambda-java-core dependency we can use the generic interface com.amazonaws.services.lambda.runtime.RequestHandler which takes two parameters, the event Type and the response type (type of the returned object).
And with the aws-lambda-java-events dependency we can type our events (provided that the Lambda is triggered by an AWS Service). In this example, we are going to create a Lambda triggered by an AWS API Gateway, using APIGatewayV2HTTPEvent for the event type and APIGatewayV2HTTPResponse for the response type. But most AWS Services that can be integrated with AWS Lambda have their own classes (see. the official GitHub repository).
With this new dependency our package is becoming a little fatter (around 1MB). By displaying the dependency tree, we can see that we are pulling now Joda Time, which is completely useless with Java >= 8.
1
2
3
4
5
[INFO] cloud.spikeseed:java-apigateway:jar:1.0.0-SNAPSHOT
[INFO] +- com.amazonaws:aws-lambda-java-core:jar:1.2.1:compile
[INFO] +- com.amazonaws:aws-lambda-java-events:jar:3.8.0:compile
[INFO] | \- joda-time:joda-time:jar:2.6:compile
[INFO] \- com.google.code.gson:gson:jar:2.8.6:compile
Some pull requests have been created, unfortunately, none have gone through so far. We can either live with it or rebuild the library without Joda Time.
Furthermore, by using the interface RequestHandler, we do not need to define the handler method in our CloudFormation template anymore:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Resources:
HttpApi:
Type: AWS::Serverless::HttpApi
Properties:
DefaultRouteSettings:
DetailedMetricsEnabled: True
ThrottlingBurstLimit: 200
FailOnWarnings: True
ApiGatewayCorretto:
Type: AWS::Serverless::Function
Properties:
FunctionName: awslambdajava-apigateway
Handler: cloud.spikeseed.Handler
Runtime: java11
CodeUri: ../../lambdas/apigateway/target/java-apigateway.zip
MemorySize: 256
Timeout: 15
Events:
ExplicitApi:
Type: HttpApi
Properties:
ApiId: !Ref HttpApi
Method: ANY
Path: /{proxy+}
TimeoutInMillis: 3000
PayloadFormatVersion: '2.0'
RouteSettings:
ThrottlingBurstLimit: 200
This time, we will not invoke the Lambda directly, we will curl the API gateway endpoint.
First, we need to find the endpoint:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
$ aws apigatewayv2 get-apis \
--profile spikeseed-labs \
--region us-east-1 \
--no-cli-pager
{
"Items": [
{
"ApiEndpoint": "https://t7av24xnq6.execute-api.us-east-1.amazonaws.com",
"ApiId": "t7av24xnq6",
"ApiKeySelectionExpression": "$request.header.x-api-key",
"CreatedDate": "2021-04-04T12:12:59+00:00",
"DisableExecuteApiEndpoint": false,
"Name": "l-use1-lambdajava-apigateway",
"ProtocolType": "HTTP",
"RouteSelectionExpression": "$request.method $request.path",
"Tags": {
"httpapi:createdBy": "SAM"
},
"Version": "1.0"
}
]
}
Then we call the endpoint curl https://t7av24xnq6.execute-api.us-east-1.amazonaws.com
Which returns our JSON object, exactly what we were expected:
1
2
3
4
{
"status": 200,
"message": "ok"
}
Logging
For any meaningful application, logs are essential and even more when running in AWS Lambda to which we have no control over.
The easiest solution is to use the logger from the Context object (logger/Handler.java):
1
2
3
4
5
6
7
8
9
10
11
12
13
public class Handler implements RequestHandler<Map<String, String>, String> {
private static final Gson GSON = new GsonBuilder().setPrettyPrinting().create();
@Override
public String handleRequest(Map<String, String> event, Context context) {
var logger = context.getLogger();
logger.log("ENVIRONMENT VARIABLES: " + GSON.toJson(System.getenv()));
logger.log("CONTEXT: " + GSON.toJson(context));
var body = Map.of("status", 200, "message", "ok");
return GSON.toJson(body);
}
}
This works well when we have a single method. But if we have multiple methods and/or multiple classes it would mean to pass the logger everywhere. Furthermore, we cannot configure the logs format. To do so, we need a real logging library like Log4j2 which is supported by AWS.
We need to add another library part of aws-lambda-java-libs (pom.xml)
1
2
3
4
5
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-lambda-java-log4j2</artifactId>
<version>1.2.0</version>
</dependency>
And then add a log4j2 configuration file:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
<Configuration status="WARN">
<Appenders>
<Lambda name="Lambda">
<PatternLayout>
<pattern>%d{yyyy-MM-dd HH:mm:ss} %X{AWSRequestId} %-5p %c{1} - %m%n</pattern>
</PatternLayout>
</Lambda>
</Appenders>
<Loggers>
<Root level="INFO">
<AppenderRef ref="Lambda"/>
</Root>
<Logger name="software.amazon.awssdk" level="WARN" />
<Logger name="software.amazon.awssdk.request" level="DEBUG" />
</Loggers>
</Configuration>
We can then use Log4j2 in our Lambda:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class Handler implements RequestHandler<Map<String, String>, String> {
private static final Logger LOG = LogManager.getLogger(Handler.class);
@Override
public String handleRequest(Map<String, String> event, Context context) {
LOG.info("ENVIRONMENT VARIABLES: {}", GSON.toJson(System.getenv()));
LOG.info("CONTEXT: {}", GSON.toJson(context));
[...]
}
}
To use slf4j with log4j2, we only have to add the following dependency:
1
2
3
4
5
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j18-impl</artifactId>
<version>2.13.2</version>
</dependency>
To be aligned with aws-lambda-java-log4j2, log4j2 dependency version we are using the version 2.13.2 of sfl4j and not the latest one.
Now we can use sfl4j in our code without any reference to a particular logger anymore.
1
2
3
4
5
6
7
8
9
10
11
12
13
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Handler implements RequestHandler<Map<String, String>, String> {
private static final Logger LOG = LoggerFactory.getLogger(Handler.class);
@Override
public String handleRequest(Map<String, String> event, Context context) {
LOG.info("ENVIRONMENT VARIABLES: {}", GSON.toJson(System.getenv()));
LOG.info("CONTEXT: {}", GSON.toJson(context));
[...]
}
}
Our new package is now almost 3MB. If we invoke the lambda and fetch the logs:
1
2
3
4
5
6
7
8
9
10
11
12
13
$ aws lambda invoke \
--profile spikeseed-labs \
--region us-east-1 \
--no-cli-pager \
--cli-binary-format raw-in-base64-out \
--function-name awslambdajava-slf4j-log4j2 \
/tmp/response.json
$ aws logs tail \
/aws/lambda/awslambdajava-slf4j-log4j2 \
--profile spikeseed-labs \
--region us-east-1 \
--no-cli-pager
We can see that the Lambda initialization time is about 1600 ms and the execution time 450 ms, adding up to more than 2s for a Lambda which does not do much.
Using the AWS SDK for Java 2.x
Contrary to the Python lambda runtime which already have the full AWS SDK (boto3), with the Java one (Corretto to be precise) we need to include it into our package.
To use the AWS SDK for Java 2.x, we first need to add a Bill Of Materials (BOM) dependency and then the dependency of the service we wish to use (ssm in this case)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
<dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>bom</artifactId>
<version>2.16.32</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>ssm</artifactId>
</dependency>
<dependencies>
We can then use the new library in our lambda:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializationFeature;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import software.amazon.awssdk.services.ssm.SsmClient;
import software.amazon.awssdk.services.ssm.model.GetParameterRequest;
import java.io.IOException;
import java.util.Map;
public class Handler implements RequestHandler<Map<String, String>, String> {
private static final Logger LOG = LoggerFactory.getLogger(Handler.class);
private static final ObjectMapper JSON_MAPPER = new ObjectMapper();
private static final SsmClient SSM_CLIENT = SsmClient.create();
private String getSsmParameter(String name) {
var response = SSM_CLIENT.getParameter(
GetParameterRequest.builder()
.name(name)
.withDecryption(true)
.build()
);
return response.parameter().value();
}
@Override
public String handleRequest(Map<String, String> event, Context context) {
try {
JSON_MAPPER.configure(SerializationFeature.FAIL_ON_EMPTY_BEANS, false);
LOG.info("CONTEXT: {}", JSON_MAPPER.writeValueAsString(context));
var body = Map.of(
"status", 200,
"message", "ok",
"secured", getSsmParameter("/lambdajava/database/rds/password")
);
return JSON_MAPPER.writeValueAsString(body);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
This time, we are not using Gson, but Jackson which is a transitive dependency coming from the SDK. In order to use Jackson, we need to add the following line (otherwise we would get an error saying that no serializer was found for the Context class):
1
JSON_MAPPER.configure(SerializationFeature.FAIL_ON_EMPTY_BEANS, false);
And we need to put our code in a try/catch which will rethrow a RuntimeException, as Jackson can throw an IOException and the handleRequest() method signature does not throw any exception.
Once again, the size of our package increases. Up to 15MB this time. If we display the dependency tree (mvn dependency:tree -Dverbose), we can see that the SDK is pulling a lot of dependencies, for a Lambda which is still not doing much.
If we invoke the Lambda and fetch the logs, we can see that things are quickly getting out of hand. The initialization time is about 3.5 s and the execution time 4.5 s, adding up to more than 8s with 512MB of memory (with less we would get an OutOfMemory exception).
AWS Lambda PowerTools
To enforce best practices and trace the execution of our Lambda we can use Lambda Powertools Java which is a set of libraries provided by AWS (see Simplifying serverless best practices with AWS Lambda Powertools Java).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<dependency>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-tracing</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-logging</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-metrics</artifactId>
<version>1.5.0</version>
</dependency>
But adding these three dependencies is not enough. As they are using Aspect-Oriented Programming (AOP), we need a plugin aspectj-maven-plugin. Unfortunately, when using Java 9 or later, the plugin used in the documentation page will not work. We have to resort to a workaround (an alternate plugin) with a specific version of aspectjtools (powertools/pom.xml).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
<build>
<plugins>
<plugin>
<!-- https://www.mojohaus.org/aspectj-maven-plugin/ -->
<!-- <groupId>org.codehaus.mojo</groupId>-->
<!-- <artifactId>aspectj-maven-plugin</artifactId>-->
<!-- <version>1.11</version>-->
<groupId>com.nickwongdev</groupId>
<artifactId>aspectj-maven-plugin</artifactId>
<version>1.12.6</version>
<configuration>
<source>11</source>
<target>11</target>
<complianceLevel>11</complianceLevel>
<aspectLibraries>
<aspectLibrary>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-tracing</artifactId>
</aspectLibrary>
<aspectLibrary>
<groupId>software.amazon.lambda</groupId>
<artifactId>powertools-logging</artifactId>
</aspectLibrary>
<!-- <aspectLibrary>-->
<!-- <groupId>software.amazon.lambda</groupId>-->
<!-- <artifactId>powertools-metrics</artifactId>-->
<!-- </aspectLibrary>-->
</aspectLibraries>
</configuration>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
<dependencies>
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjtools</artifactId>
<version>1.9.6</version>
</dependency>
</dependencies>
</plugin>
</plugins>
</build>
After this configuration we only have to use annotations (@Tracing and @Logging in this case, we are not using @Metrics). Furthermore, with the parameter logEvent = true, every event will be logged automatically.
1
2
3
4
5
6
7
8
9
10
11
12
13
import software.amazon.lambda.powertools.logging.Logging;
import software.amazon.lambda.powertools.tracing.Tracing;
public class Handler implements RequestHandler<APIGatewayV2HTTPEvent, APIGatewayV2HTTPResponse> {
@Tracing
@Logging(logEvent = true)
@Override
public APIGatewayV2HTTPResponse handleRequest(APIGatewayV2HTTPEvent event, Context context) {
[...]
}
}
To finish the configuration we need to add few environment variables to our Lambda and increase the timeout to both the Lambda and the API Gateway:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
ApiGatewayCorretto:
Type: AWS::Serverless::Function
Properties:
FunctionName: awslambdajava-powertools
Handler: cloud.spikeseed.Handler
Runtime: java11
CodeUri: ../../lambdas/powertools/target/java-powertools.zip
MemorySize: 512
Timeout: 30
Tracing: Active
Environment:
Variables:
POWERTOOLS_SERVICE_NAME: java-powertools
POWERTOOLS_LOG_LEVEL: DEBUG
Events:
ExplicitApi:
Type: HttpApi
Properties:
ApiId: !Ref HttpApi
Method: ANY
Path: /{proxy+}
TimeoutInMillis: 30000
PayloadFormatVersion: '2.0'
RouteSettings:
ThrottlingBurstLimit: 200
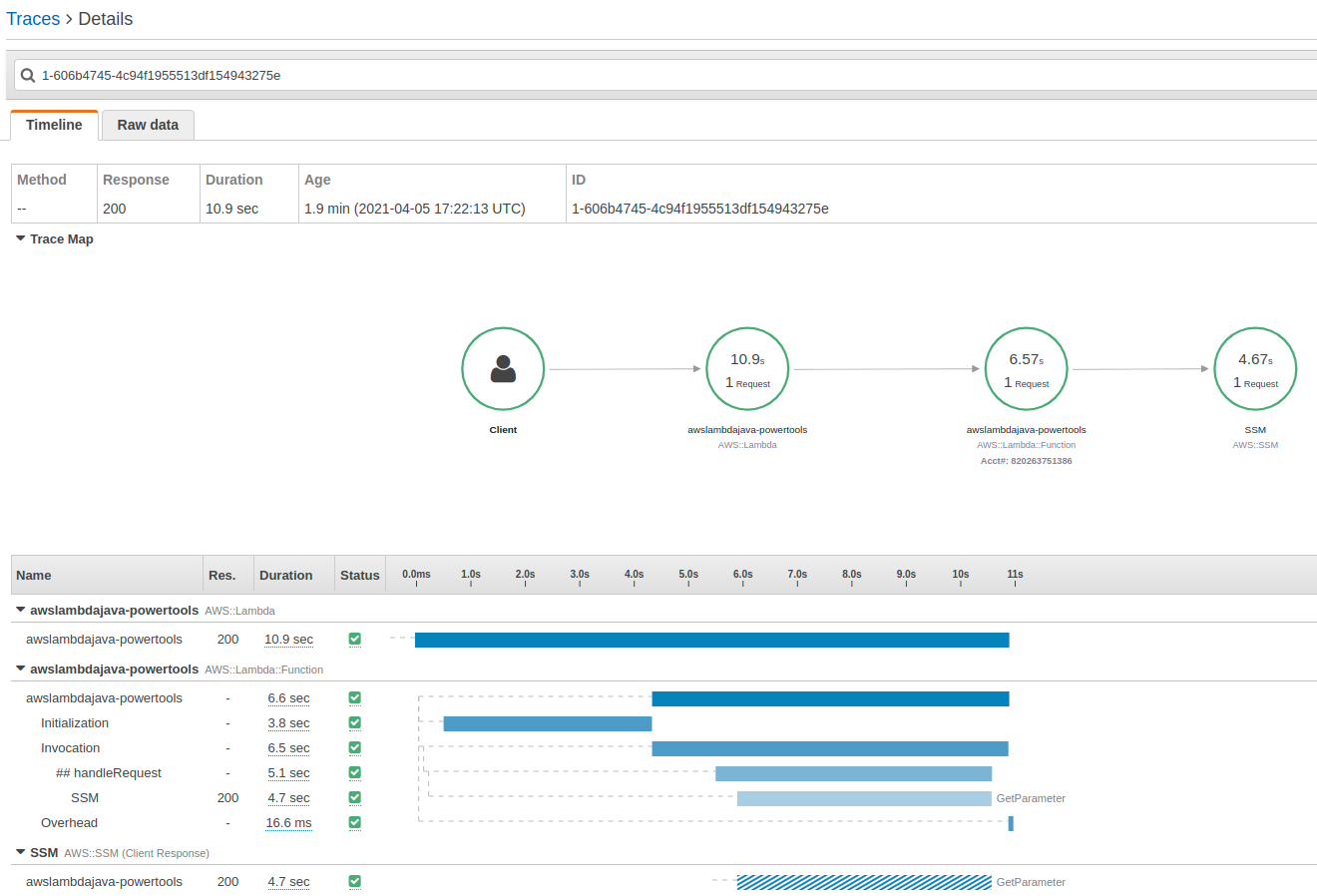
Once again, the package size increased to 17MB, the initialization time is 6.6 s and the execution time 3.8 s.
Now that we have AWS X-Ray enabled, we can see where we are spending time:
Testing
Unit Testing requires mocking all I/O operations. Therefore, there is no problem on this side. However, no matter the programming language testing becomes harder and harder the more we add external services, but the same principles apply whether our application is a Lambda or not.
When our application is composed of multiple micro-services and uses AWS, we can use Docker, Docker compose, or even a local Kubernetes setup with Minikube or Kind, in addition to tools like LocalStack which try to replicate an AWS environment with Containers. But nothing can better reproduce an AWS environment than a real AWS environment. And with Infrastructure as Code, we can spawn a testing environment in minutes.
Therefore, Integration, Load and End-to-End testing should be done against a deployed infrastructure/application in AWS, using standard testing tools like Jmeter, SoapUI, Postman, Cypress, Selenium, etc.
Conclusion
In this article we have seen that using Java for AWS Lambda is not so complicated. But we should always keep in mind that we should always use the right tool for the job. If we can write a lambda in 100-line of code using Python or NodeJS, this code could be inlined in a CloudFormation template and there would be absolutely no added value to use Java.