
Yohan Beschi
Developer, Cloud Architect and DevOps Advocate
Serverless Architectures - The answer to everything?

With Serverless infrastructures, after Infrastructure as a Service (IaaS), Platform as a Service (PaaS) and Software as a Service (SaaS), we’ve entered in the Function as a Service (FaaS) era. The Function (as in a programming language function) becomes the core building block of an infrastructure.
The idea of only bringing the code of our applications and leaving the hassle of managing all the underlying infrastructure to a third-party provider is appealing. Lowering maintenance cost and our TCO, having feature-focused teams (as in spending time mostly, if not exclusively, on features and not unrelated topics) and in the endless code to maintain, means less problems and more importantly a faster time to market, which inherently leads to happier customers. These are the selling points of serverless architectures, but is it the solution to every problem, and are we prepared to sell our house to rent and leave in a box (imagine the capsule hotels)?
Before we dive deeply into the subject at hand, let’s define what, as IT engineers, we all want:
- Security. Of the servers and all the data.
- High Availability. In a highly competitive market, we can’t afford down times.
- Fast scale up and down. Responsiveness is a key feature. The time when users were ready to wait 30 seconds after clicking on a button to have a result is in the past.
- Reproducibility. We want to be able to move our infrastructure (applications included) from one place (environment or AWS region), as-is, to another, within minutes.
- Simplicity. No matter how we put it, this is not String Theory, complexity is only the result of bad design.
Traditional AWS Infrastructure
With that in mind, let’s imagine a theorical company infrastructure for a single application, with components that we’ll find almost everywhere.
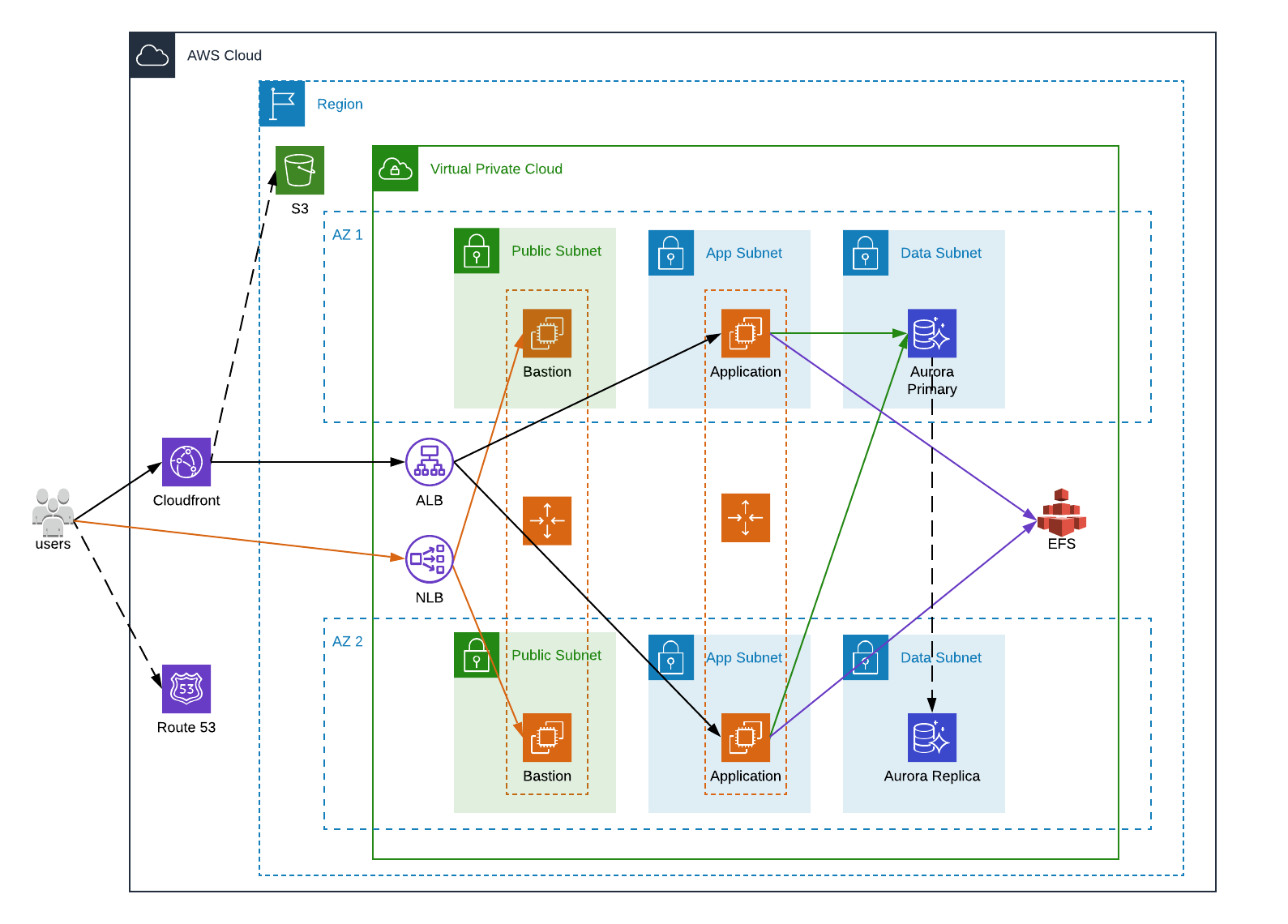
Let’s check our requirements:
- Security. For the sake of simplicity, the security is not depicted in the schema. We will consider that:
- The application can only be accessed through HTTPS;
- The application handles the user log in mechanism with the passwords stored, securely (hash, salt…), in the database;
- The Network ACLs and Security Groups have been configured correctly;
- All data resources (EBS, RDS, EFS and S3) are encrypted using KMS
- High Availability is achieved with auto scaling groups spanning multiple AZs and a multi-AZ RDS, and the usage of highly available AWS services like Route 53, CloudFront, S3 and EFS. More importantly, there is no single point of failure.
- Fast scale up and down is dependent on the auto scaling groups, and “fast” in this case is somewhat relative.
- Reproducibility. This cannot be represented in the schema, but it’s worth mentioning that reproducibility is achieved through everything as code (AMI provisioning and infrastructure creation)
- Simplicity. Even if for an untrained eye it doesn’t seem to be, we could hardly have a simpler architecture meeting our requirements.
Unfortunately, we are not done. Almost all components used are managed by AWS which make our lives easier but the EC2 instances are not and this is an essential part of the Ops work (pun intended). All servers must be patched and up-to-date as much as possible, and tools must be installed and configured, to cite a few: AWS CLI, AWS Cloudwatch, AWS SSM and AWS Inspector agents, etc. Of course, this must be tested before going to production and it’s usually a hurdle to find the updated package breaking our application, if any.
As a result, in a traditional architecture, even for one simple application we have a lot of things to care about. Will a serverless architecture make all the pain go away?
Simple AWS Serverless Infrastructure
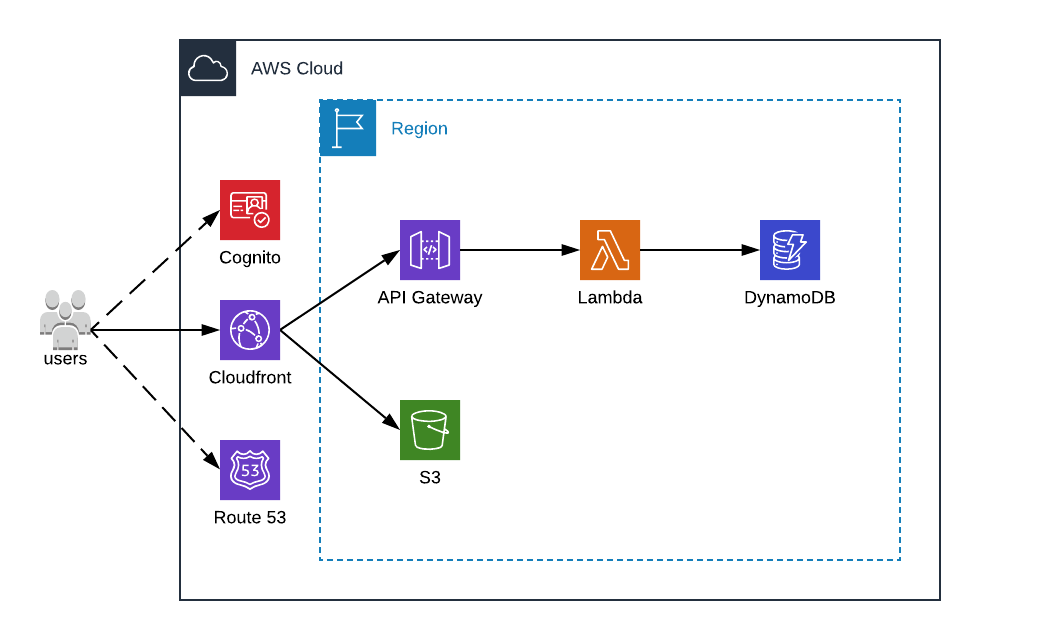
This is the kind of schema we usually find associated with servlerless architectures. The infrastructure is much simpler and we are only using managed services. Unfortunately, this chart is a lie. Contrary, to the too often seen alchemy formula, we usually cannot trade a SQL database for a NoSQL database (and even less DynamoDB) and in the process, we’ve lost the EFS because we have no way to mount it in a Lambda (some use cases could easily use S3 instead).
A more, real chart would be as follow:
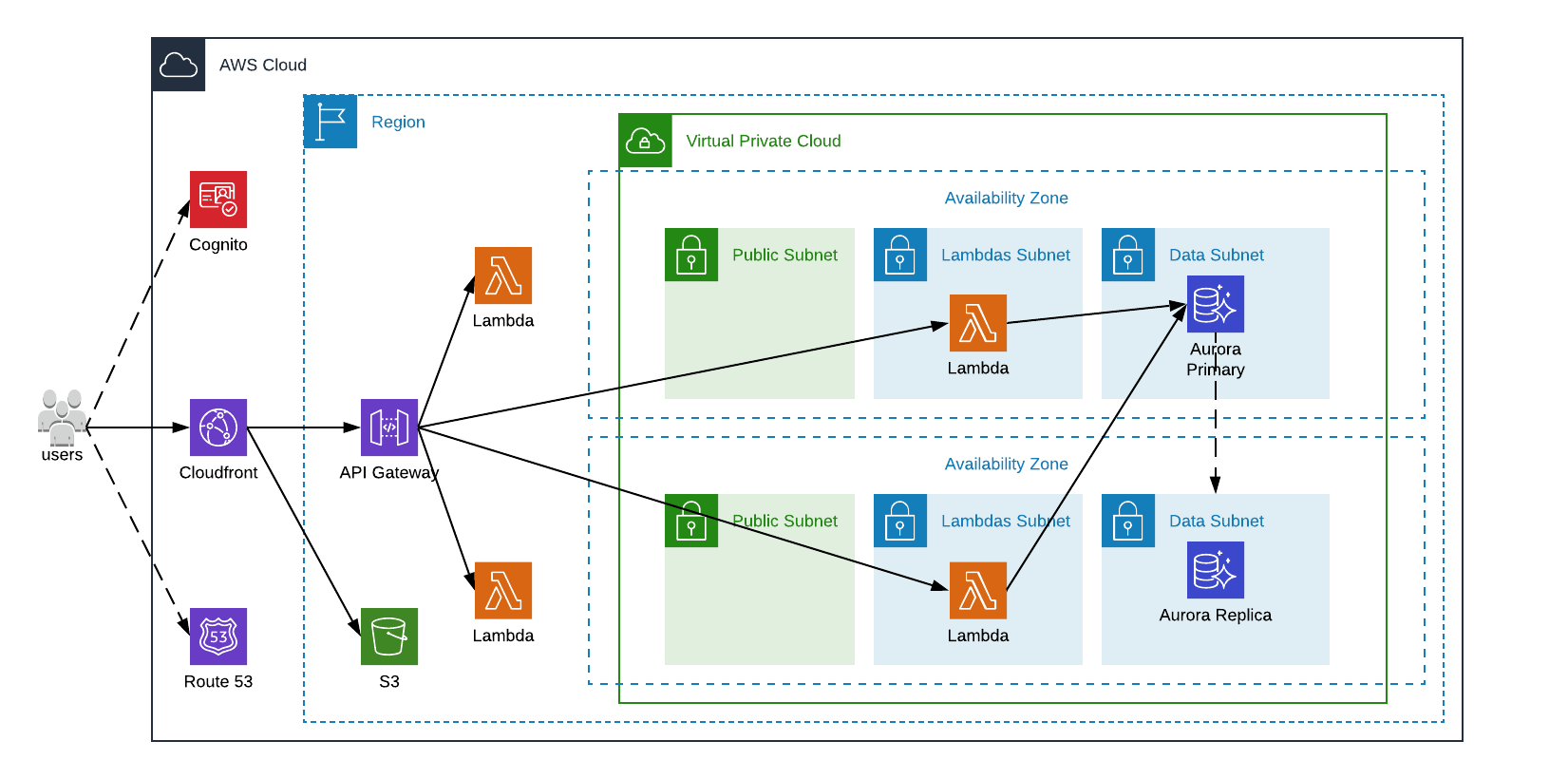
In the end, even if the chart seems more complex than the previous one, we still have only managed services, which is the whole point of serverless.
That being said, let’s review the much-anticipated components making our new infrastructure serverless.
Starting with the usual services for a veteran AWS user, AWS Route 53 is a scalable DNS service, the entry point of our application. AWS S3 is a key/value object store, containing all our static files like HTML, CSS, JS and images and AWS CloudFront is AWS CDN, targeting S3 resources and caching them at edge locations.
Simply put, AWS API Gateway allows us to map REST path requests and WebSocket to other AWS services like EC2, DynamoDB, AWS Lambda, etc. It supports all 7 standard HTTP methods and, text and binary payloads (limited to 10MB. Over this size we must upload our files directly to S3). This mapping can be easily configured using OpenAPI, a simple way to describe our API in JSON or YAML.
AWS Cognito is AWS managed SSO, where we can define users, use IAM users or identity federation to use third party SSO such as Facebook, Google, or any SAML-based identity provider.
Last, but not least, the core component of any serverless infrastructure, the Function, which in AWS is AWS Lambda. Lambdas are triggered by events, usually coming from other AWS services such as CloudFront, API Gateway, S3, DynamoDB, Kinesis Streams, SNS Topics, SQS Queues, AWS IoT, Cognito Sync Trigger, CodeCommit, AppSync, Alexa, CloudWatch logs and events, EC2 Lifecycle, etc. But not only. They can be invoked through the AWS SDK or even be scheduled. All of this make Lambdas extremely versatile.
Here a few use cases:
- Web Apps/Mobile backends
- CRON jobs
- ETL jobs (Extract, Transform and Load)
- Infrastructure automation
- Data validation
- Security/Governance remediation
Every time a Lambda is invoked, under the hood, AWS will launch a new worker. Which means that we don’t have to handle any concurrency. Lambdas are stateless and do only one thing at a time.
AWS Lambda dynamically scales function execution in response to increased traffic, up to 1000 concurrent executions (this limit can be increased). And we only pay the execution time by 100ms increments depending on the memory allocated to it, from 128 MB to 3008 MB.
AWS Lambda natively supports C#, Go, Java, Node.js, PowerShell, Python, and Ruby code. The principle is quite simple, we only need to create a file containing a special function (named a handler), zip it and finally upload it to create the AWS Lambda. On the security side, the code is stored in S3 and encrypted at rest.
As a few lines of code are worth a thousand words, here is a simple example of a Lambda, in Python, responding to an HTTP request with a 200 status and a text/plain payload containing the text: “Hello from AWS Lambda”.
1
2
3
4
5
6
7
8
def handler(event, context):
return {
'statusCode': 200,
'headers': {
'Content-Type': 'text/plain'
},
'body': 'Hello from AWS Lambda'
}
We won’t go into much more details as it is not the subject here, but let’s note that if we activate the “proxy integration” on the API Gateway side, the event object will have the complete HTTP message in JSON, with binaries (in payload) encoded in base64.
Unfortunately, we don’t live in a perfect world and we must bear in mind that there are few limitations that make AWS Lambdas not suitable for all use cases:
- The compressed package cannot be more than 50 MB
- The uncompressed package cannot be more than 250 MB, layers included (Layers can be view as shared libraries)
- The execution time cannot exceed 15min
- The payload cannot exceed 6 MB
- Completely stateless, no cache or connection pools
- No filesystem. We only have access to a temporary folder. We cannot mount an NSF or SMB filesystem
- Some languages suffer from a long Cold Start
- Runtimes versions are almost always lagging. For example, only Java 8 and 11 are available.
- API gateway for Lambda integration has a timeout of 29s
AWS Lambda Cold Start
After a Lambda has been created, it is not launched nor put in idle state. Only after the first invocation:
- a lightweight micro-virtual machine (microVM) is launched;
- the code is copied inside the microVM;
- then the lambda is initialized;
- and finally executed
These four steps are what we call the Cold Start.
Depending on the language, this time can be long. Languages that require a “language” Virtual Machine such as Java or C# will have a longer Cold Start than compiled languages (Go) or interpreted ones (Python, NodeJS, etc.). After its first execution a lambda goes into idle state (or warm stand by) until another invocation or the destruction of the microVMs. Unfortunately, AWS doesn’t provide the idle timeout for a microVMs to be recycled (some unofficial sources say between 30 and 45 min). Moreover, it’s not because we never reach the idle timeout that the microVMs will not be recycled (again from unofficial sources, it would be around 7 to 8 hours). And finally, this Cold Start does not happen only once. If we have 100 concurrent incoming requests, we will need 100 lambdas up and running. In other words, our 100 requests will suffer from a Cold Start. Needless to say, using Java and Spring with a 20 seconds startup is probably not the best idea.
But there is a way to circumvent this inconvenience: keeping the lambdas warm by scheduling pseudo pings through CloudWatch events. Of course, the more we need concurrent lambdas, the more expensive it will get, and nothing will prevent an incoming request occurring at the same time of a ping, which will result in either the creation of a new microVM or a throttling error.
Ultimately instead of squaring the circle we should probably find a lean solution with the tools at our disposition. And if we don’t, lambdas are maybe not the best tool for the job.
Let’s mention that in December 2019, AWS announced Provisioned Concurrency for AWS Lambdas. It is a completely different pricing model, we don’t pay for the execution duration only.
Conclusion
With serverless computing, our applications still run on servers, but all the server management (bare-metal, virtual machines and web/application servers) is done by AWS (or any other decent cloud provider). This can be a huge relief, but this does not answer the initial question. Can serverless architectures replace all traditional ones? The answer is clearly no. We’ve seen the official limitations of AWS Lambda, but we should not elude the more insidious ones like the inability to have a database connection pool (will be available in the near future RDS Proxy with AWS Lambda), any local in memory cache, or mount a shared filesystem.
To be fair, serverless architectures are still in their infancy and we should not discard them so easily. They are already a powerful tool in our toolbox today, and we’ll probably hear more and more about them in the next few years.
On a side note, it is important to remember that we got to this point after a slow revolution started 30 years ago by Kent Beck, Ron Jeffries, Martin Fowler, and al. who contributed to the adoption of Unit Testing, TDD, XP, Continuous Integration, Delivery and Deployment. In other words, all the tools that we have today, and make us more confident when we push our code which will be in production minutes after.
To conclude, if you have an hour to spare, I encourage you to watch a much insightful video about the inner working of AWS Lambda (the part you want to delegate to AWS).