
Yohan Beschi
Developer, Cloud Architect and DevOps Advocate
Going serverless with AWS
Serverless has been a trending topic for the past 6 years. S3 has been recently elected the greatest cloud service of all time and Lambdas got the 2nd place. On paper it’s a wonderful type of architecture, but where are we today and can AWS Lambdas compete with plain AWS EC2 instances ?
A great book from two former AWS engineers triggered the idea of this article:
Lambda is great — definitely one of the good parts of AWS — as long as you treat it as the simple code runner that it is. A problem we often see is that people sometimes mistake Lambda for a general-purpose application host. Unlike EC2, it is very hard to run a sophisticated piece of software on Lambda without making some very drastic changes to your application and accepting some significant new limitations from the platform.
AWS the Good parts, Daniel Vassallo & Josh Pschorr, 2019
Except for being provocative, is this statement relatable in any way and if so, does it apply to other fundamental Serverless AWS services ?
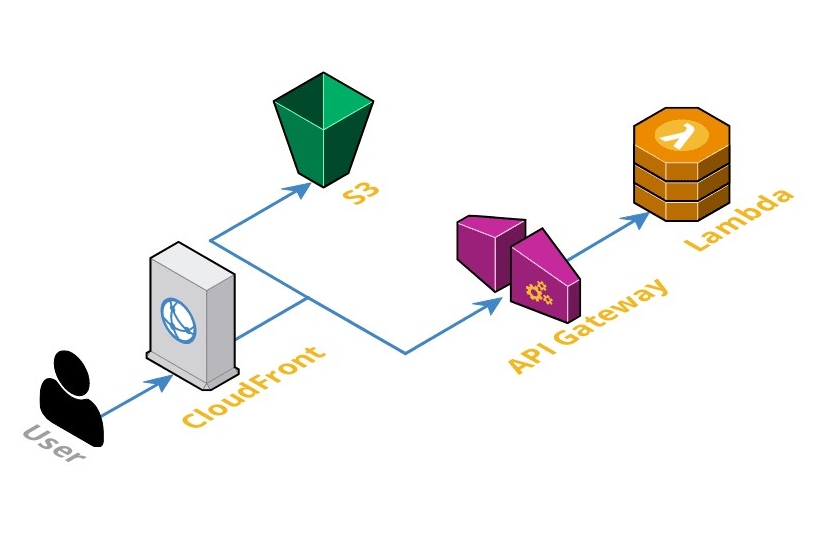
In a previous article (Serverless Architectures - The answer to everything?) we’ve already described the main differences between traditional and serverless architectures, and given an overview of AWS Services that can be used in a serverless architecture. This time, we will explore four essential services in details:
Please note that we will completely ignore WebSocket features available with AWS CloudFront and AWS API Gateway.
AWS S3 - Static Web Hosting
AWS S3 can be used to host static websites. Once “Static website hosting” is enabled and the correct Bucket Policy has
been configured, we are able to access files from a browser using a URL like
http://<bucket-name>.s3-website.<Region>.amazonaws.com or http://<bucket-name>.s3-website-<Region>.amazonaws.com
(a dash or a period between website and Region),
S3 acting much like an HTTP server; supporting only GET, HEAD and OPTIONS HTTP methods.
AWS S3 will serve index.html (or any file configured to be the index document) even if we use http://<bucket-name>.s3-website.<Region>.amazonaws.com without /index.html.
And if a resource (object in S3) doesn’t exist, it will display our error document.
Furthermore, it is important to note that “static”, only refers to the server side. We won’t be able to generate HTML files dynamically but we can still serve Javascript files that will be executed in our users browser, which can call API endpoints.
Custom Domain
For absurdly low monthly fees, we can easily host a static website using S3 URLs. But we usually want to use our own domain (eg. http://example.com and/or http://www.example.com). To be able to create a record in Route 53 one constraint is forced upon us by S3. The bucket name must be the same as the custom domain (or subdomain).
Therefore, we must:
- create a bucket named
www.example.com - upload the static resources
- enable the “Static website hosting” with the option “Use this bucket to host a website”
- create in AWS Route 53
- an ALIAS record
www.example.com A ALIAS s3-website-eu-west-1.amazonaws.comor - a CNAME record
www.example.com CNAME www.example.com.s3-website.<Region>.amazonaws.com.
- an ALIAS record
Then, if we want to be able to use http://example.com we need to:
- create a bucket named
example.com - enable the “Static website hosting” with the option “Redirect requests” and the target option
www.example.com - create in AWS Route 53
- an ALIAS record
example.com A ALIAS s3-website-eu-west-1.amazonaws.comor - a CNAME record
example.com CNAME example.com.s3-website.<Region>.amazonaws.com.
- an ALIAS record
When a user will try to access http://example.com AWS S3 will respond with a 301 redirection to http://www.example.com.
Limitations
If AWS S3 Static Web Hosting can be used for multiple purposes, it has some limitations:
- HTTPS cannot be used directly. We need an AWS CloudFront Distribution in front.
- Buckets (and objects in the buckets) must be public (and not encrypted).
- The S3 URL will still be available even with a custom domain (requests will be redirected to our main custom domain)
AWS CloudFront
With a simple S3 Static Web Hosting configuration, even if S3 is a Global Service, S3 Buckets and their data live in a specific region. Therefore, when we create a bucket in Ireland (eu-west-1), Australian users will fetch the resources from the AWS Data Centers in Ireland. Which results in a very high Round Trip Time (RTT).
To solve this problem we can use AWS CloudFront, the AWS Content Delivery Network (CDN). Instead of being served from specific regions, resources will be fetch from Edge locations.
For example, a user in Sydney accessing http://www.example.com/index.html will most likely go through the Sydney Edge location. If the resource is found there it will be returned, otherwise the request will be forwarded to the S3 bucket in Ireland. Then the response will be cached at Sydney’s edge location, for any subsequent requests, for 24h by default.
But before continuing, let’s go back a little. To create an AWS CloudFront Distribution we need to specify at least one origin accessible through a public URL and supporting HTTP requests like an S3 Bucket, an ALB, an EC2 instance, an API Gateway or even a resource outside AWS. The communication between an AWS CloudFront Distribution and the origin can be over HTTP or HTTPS (in HTTP/1.1 only).
We can configure more than one origin using URL paths to route the requests to a specific origin. For example, all /api/*
requests could be forwarded to an AWS API Gateway and all the other ones to an S3 Bucket.
By using AWS CloudFront in front of an S3 Bucket almost all of the limitations of S3 Static Web Hosting are lifted:
- We can use any bucket name we want. The name of the bucket doesn’t matter and we don’t need to enable “Static website hosting”
- Our buckets can be private (the objects remaining unencrypted)
- We can associate an AWS ACM Certificate to expose our website/web application in HTTPS. We can even ask AWS CloudFront to redirect all HTTP requests to HTTPS.
- Through an Origin Access Identity we can restrict the access to an S3 bucket to a single AWS CloudFront Distribution. Consequently forbidding access from bucket URLs (http://<bucket-name>.s3-website.<Region>.amazonaws.com).
Furthermore, when creating an AWS CloudFront Distribution a FQDN is generated based on the CloudFront Distribution ID (<distribution_id>.cloudfront.net). Like for S3 FQDNs, we can create ALIASes or CNAMEs pointing to the CloudFront Distribution.
Caching
Caching is one of the main benefit of AWS CloudFront, which, for the users, is translated in faster response time and for us less compute time on our backend and therefore can reduce the size/number of EC2s or the number of call to AWS API Gateway and to AWS Lambda. In other word it can reduce the costs. But the cost of the egress traffic from AWS CloudFront should not be overlooked for a high traffic website.
Even if AWS CloudFront supports all 7 standard HTTP methods (HEAD, GET, OPTIONS, POST, PUT, PATCH, DELETE), only the 3 first ones will be cached. It is important to take into consideration that requests are not cached only based on the requested URLs. AWS CloudFront cache keys are composed by Query strings, Cookies and Headers that are allowed to be forwarded to the origins. In other words, session Cookies, usually unique for each users and even sometimes different for every request will result in “cache miss” every time. The requests will always be forwarded to the origin.
The following document describes how to Optimize Content Caching and Availability and how it works.
Limitations
AWS CloudFront offers caching at Edge locations, the use of HTTPS and even DDoS mitigation due to its distributed nature.
But it’s important to remember that AWS CloudFront is not a reverse proxy. Even if we can route requests to different origins depending on the request URLs or add a root context, we cannot rewrite URLs or responses out-the-box. AWS Lambda@Edge can help reproducing some features of a reverse proxy but at the cost of the response time.
AWS API Gateway
With AWS S3 and AWS CloudFront we can have a high-available and fast/cached website at a very low cost (again depending on the traffic). But with a static website we can’t do much. Even the most basic website will have at least a contact form that need to be handled dynamically. The way to do it in a Serverless fashion is to use AWS API Gateway and AWS Lambdas.
Recently, AWS launched HTTP APIs (a new flavor of API Gateway) to create RESTful APIs with lower latency and lower cost than REST APIs, but with less features. Like always, choosing between the two will depend on our needs.
For both type of APIs the main concepts remain the same. We define a triplet composed of:
- a resource path (eg.
/books); - a HTTP method (eg.
GET) and; - an integration type (eg. AWS Lambda). We will focus on AWS Lambda integration here.
There are three main architectural movements to structure an API:
- one resource, one HTTP method, one Lambda
GET /books GetBooksLambdaGET /users GetUsersLambda
- one group of resources, all HTTP methods, one Lambda
GET /books BooksLambdaPOST /book BooksLambdaGET /user/1 UsersLambdaDELETE /user/42 UsersLambda
- catch all - every resources and HTTP methods are forwarded to a single Lambda
GET /books MyApiLambdaGET /users MyApiLambda
The first one push the microservice architecture to the limit. The second use a regular microservice approach. And the third still rely on a more monolithic approach. With solution 2 and 3, part or all the routing must be done at the Lambda level. But, as a matter of fact, it is only a philosophical battle, the actual implementation will be guided by
- AWS Lambda limitations and shortcomings that we’ll see shortly
- how the project is structured and Lambdas are packaged
- how everything will be deployed using AWS CloudFormation (or any similar tool)
It’s worth mentioning that we can create APIs with slightly modified Swagger/OpenAPI 3.0 files in JSON or YAML, containing some (unspecified) extra AWS specific parameters. To figure out how to configure an AWS API Gateway correctly we usually create everything manually in the AWS console and use the export to Swagger/OpenAPI 3.0 feature.
On paper, everything seems quite easy, but in practice the learning curve is steep. And we need to face some weird decisions on AWS part. For example, after creating or updating an API we cannot use it directly, we need to deploy it (publish it - not to be confused with deploying the AWS CloudFormation template creating/updating the API) on a stage (eg. dev, production, etc.).
We will then be able to access our API with the following URL https://<api_id>.execute-api.<Region>.amazonaws.com/<stage_name>. (The HTTP API introduced the concept of “default stage” which removes the stage name from the URL, if used).
We can of course use a custom domain to access our API. And this time, in HTTPS (AWS API Gateway doesn’t support HTTP) with an ACM certificate.
Furthermore, by using an Edge Optimized API Gateway endpoint, AWS will provision (and manage) a CloudFront Distribution in front of our API Gateway. Unfortunately, we won’t have access to it and therefore be able to configure it. To do so, we need a Regional API Gateway endpoint and create our own CloudFront Distribution. We can even share the CloudFront Distribution used to serve static resources from S3 and add a new origin pointing to the API as mentioned previously.
Limitations
In addition to being difficult to configure, AWS API Gateway comes with several limitations:
- An API can serve at most 10,000 requests per second
- The payload of a request cannot exceed 10 MB
- API gateway for Lambda integration has a maximum timeout of 29s (API REST) / 30s (API HTTP)
- When behind an AWS CloudFront Distribution the
Hostheader cannot be forwarded from CloudFront to an AWS Lambda through an AWS API Gateway
One might say that the third limitation is not really one. If an action takes more than 2s, the user will most likely close the tab of our website and never come back again. And long running processes should occur asynchronously.
The fourth bullet point, can be worked around by creating one CloudFront Distribution by domain and use a custom header
(eg. X-Forwarded-Host) containing the name of the domain.
AWS Lambda
The last, but not least, topic to explore in our deep dive is AWS Lambda, the main component in a serverless architecture.
The first step, when starting a serverless project is to choose the programming language to use to code the Lambdas. AWS Lambda natively supports multiple languages. Unfortunately not all are equals, Java and C# raw speed is faster than Python or Node.js, but the initialization time of the Lambdas in the former languages is much slower. Needless to say, that using SpringBoot in a Lambda is probably the worst idea one could ever have.
But that’s not all. When not used, Lambdas only exists in an S3 Bucket. Therefore, no matter the language, when an AWS API Gateway calls a Lambda the following steps occur:
- a lightweight micro-virtual machine (microVM) is launched;
- the code is copied inside the microVM;
- then the Lambda is initialized;
- and finally executed
This is known as the cold start and for languages like python or Node.js it takes about 500ms/1s before the execution of the Lambda. Even if after being called once the Lambda will remain “warm” for some time (the actual time is not disclosed by AWS), there is no way around it. For every HTTP request to the API Gateway, one instance of a Lambda is executed. If two requests occur concurrently two Lambdas instances are required. Using provisioned Lambdas (Lambdas always warm) will help (we don’t need a warmup mechanism anymore) but it won’t solve the issue of an unexpected concurrent clients coming along.
Furthermore, the cost of Provisioned Concurrency should be not overlooked. We are no longer in a pay-for-usage model. A single Lambda provisioned with 128 MB will cost around $35/month which is 10 time higher than a single t3.nano EC2 instance.
Limitations and shortcomings
AWS Lambda comes with a long list of limitations:
- The compressed package cannot be more than 50 MB
- The uncompressed package cannot be more than 250 MB, layers included (Layers can be view as shared libraries)
- The payload cannot exceed 6 MB
- Completely stateless, no cache or connection pools (Amazon RDS Proxy will solve this issue in the future)
- No filesystem. We only have access to a temporary folder. We cannot mount an NSF or SMB filesystem
In addition to the above service limitations, AWS Lambda makes, occasionally, even the simplest things hard to handle. And it’s especially true for Lambdas in Python and Node.js, the two mostly used languages with AWS Lambda.
One issue is the simplest use case of any website, sending the values of a form to a backend usually with the
Header Content-Type: multipart/form-data. Something that every web application server can handle. But with AWS Lambda,
we receive the body of the POST request in a raw format looking like this:
1
2
3
4
5
6
7
8
9
--boundary
Content-Disposition: form-data; name="field1"
value1
--boundary
Content-Disposition: form-data; name="field2";
value2
--boundary--
Therefore, we have to parse this body on our own, using a library and making sure we are using the right Encoding.
Another issue is the fact that HTTP Request and Response messages are JSON objects. Everything need to be loaded in memory, we cannot stream a big request or response payload. The main reason is that in AWS architecture best practices, AWS Lambda is not supposed to be used this way. Files should be uploaded and downloaded through S3, optionally with signed URLs, signed cookies or an API KEY.
A simple example
It’s near to impossible to list all the issues one could face setting up a Serverless infrastructure using AWS, and even more in a blog post. But let’s explore a very simple use case. A website with static resources (html, css, javascript, images, fonts, etc. file) and few forms (with text and “small” files upload). Nothing very fancy. We could have a Database as-well, but it’s not important. Our only requirements is to have a website that can server pages in multiple languages and be SEO friendly.
Now let’s take 5 min and imagine how we would implement this using a traditional architecture with EC2 instances. And then 5 more, in a serverless way.
There are 3 alternatives to have a multi-language website:
- a domain name by country (eg. www.example.de, www.example.fr, www.example.lu, etc.)
- subdomains by language (eg. de.example.com, en.example.com, fr.example.com, etc.)
- the language in the URL path (eg. www.example.com/de, www.example.com/en, www.example.com/fr, etc.)
For a small website, only the third option can used. On a SEO point-of-view, different domains means different indexation and therefore more work. As with the third option, backlinks in multiple languages will add up in the reputation of the website (assuming that the appropriate HTML tags are used).
But with this solution, one issue arise. We need to redirect the user to the appropriate language when using
https://www.example.com. Having a default language is not very user-friendly. And doing this in Javascript should be avoided.
To do so, we can use the Accept-Language header (and subsequent requests using a cookie).
Unfortunately AWS CloudFront cannot route requests based on header and even less when there is some logic to be applied.
Accept-Language containing weighted values (en-US,en;q=0.9,de;q=0.7,*;q=0.5) the most appropriate language based on the
user preferences and what the website can serve must be computed. We could still use CloudFront by forwarding all the requests
starting with the following paths: /assets, /de, /en, /fr to an S3 buckets and everything else to another backend.
But we would not be able to serve error pages in the correct language, as error pages are configured at the Distribution Level
and not the origin level.
Going back to being SEO friendly, we have one last problem to solve: redirections. Two redirections is acceptable but we should always target one redirection at most. Therefore, a user accessing the website using http://example.com should be redirected to https://www.example.com/<language>. Which means 3 modifications are necessary on the original URL:
- HTTP to HTTPS
example.comtowww.example.com- language resolution
With a traditional architecture we would most likely create a VPC, with an ALB (incurring a $20 monthly fee), provision
two t3.nano EC2 instances and code the website in PHP, Python or Node.js. All language and redirections computing being
done at the backend level. We could still use an AWS CloudFront distribution to leverage caching and serve assets
(css, javascript, images, fonts, etc.) stored in an S3 bucket. HTML files could be stored in S3 as-well, but they would have to
be served by the backend in order to return the page in the correct language. There should not be any issue with handling the forms.
Only processing uploaded files should require a little extra work.
With a Serverless architecture we will have first to decide which one of the 3 ways to structure AWS API Gateway resources we should use.
To then be able to decide the layout of our project, the number of git repositories and, the build and deploy tool to use.
As mentioned before, the issue with solution 1 and 2, which require multiple AWS Lambdas, is the cold start. The more Lambdas we have, the more chance our users will encounter a cold start. Which is not very user friendly. Moreover, multiple Lambdas means multiple Lambdas to package and deploy, and AWS Lambda Layers to manage. Fortunately, we have multiple tools that can help: AWS CDK, AWS SAM, the Servless framework, etc. The trade off is always the same. The more we add abstraction, the more we will have restrictions and the more it will be difficult to break out free of these restrictions.
That being said, these tools not being part of this, - already long article -, let’s fast forward to the implementation.
AWS S3 and AWS CloudFront
- All static resources should be stored in an S3 Bucket.
- To be able to handle the example.com to www.example.com redirection we should have 2 AWS CloudFront Distribution,
one for each domain. And a Customer Header for each Distribution (eg.
X-Forwarded-Host: example.comandX-Forwarded-Host: www.example.com) - Both AWS CloudFront Distributions should be able to serve files under
/assetsdirectly, from a unique S3 Bucket. Every other requests should be forwarded to an AWS API Gateway
AWS API Gateway
To keep thing simple we could use the catch all (resources and HTTP methods) solution and forward every request to a unique Lambda.
Furthermore, in order to be able to upload binary files like pictures, we need to enable the binary support on our API Gateway by specifying every Media Types that could be used while uploading files.
We could use S3 to upload files but it requires a lot more work, which is unnecessary for a small website.
AWS Lambda
Finally, our unique AWS Lambda would do exactly what would our application on an EC2 instance:
- Handle errors
- Compute the redirection if needed (using the headers
X-Forwarded-ProtoandX-Forwarded-Host). - Compute the language to use and return the appropriate HTML pages (along with a
Set-Cookieheader to avoid guessing the language for the subsequent requests or if the user choose one explicitly) - Handle the forms using the appropriate libraries
A word of advice. Do not send more than one request at a time to an AWS API Gateway to display a single HTML page. And of course do not serve all static resources through AWS Lambda. Today, even a simple website need many resources. Therefore, a browser usually retrieves the main resource (an HTML page), then parses the document to build a DOM and collect all the other resources needed to display the page correctly. Once collected, if the resources are not deferred, the browser is going to make HTTP requests in parallel to retrieve them. Which means that for 10 resources, 10 AWS Lambda instances will be launched for a single user.
Conclusion
Today, no one can tell if a Serverless application can be developed and released much faster than a regular application living on an EC2 instance. The only thing we known for sure is that the running costs will be lower (until some point).
Is worth it or not ? Are we accepting the limitations ? Are we ready to accept the learning curve and the training required for our teams to be able to build Serverless architectures efficiently on AWS ? Are we going to have a feature-focus team or team looking for workarounds every step of the way ?
There is not a unique answer to all these questions. And at this point, at least for now, it’s only a matter of preference and investment.
Before wrapping up, it’s worth mentioning that all four described AWS Services have requests logging capabilities and even X-Ray integration for AWS API Gateway and AWS Lambda which is a nice touch.