
Yohan Beschi
Developer, Cloud Architect and DevOps Advocate
Cloudformation with Ansible

When working with AWS, Cloudformation should be the choice by default for Infrastructure as Code. Even if Cloudformation is far from being perfect and a lot of other tools are available, its ease of use and integration with AWS makes it an invaluable asset for our infrastructures. With a little work, we can even write generic Cloudformation templates and control the creation of resources using conditions. But for automation, AWS CLI is a pain to pass parameters or tags, deploy the same stack in multiple regions, etc. It’s where Ansible comes to the rescue.
Ansible is an open-source software provisioning, configuration management, and application-deployment tool. It runs on many Unix-like systems, and can configure both Unix-like systems as well as Microsoft Windows. It includes its own declarative language to describe system configuration.
Ansible was written by Michael DeHaan and acquired by Red Hat in 2015. — Wikipedia
All the source code presented in this article is available in a Github repository.
Requirements
To be able to execute the code presented in this article, we will need:
- An AWS Account
- An IAM user with programmatic access
- The AWS CLI with a profile configured (named
spikeseed-labsin the examples) - Ansible (on Windows Windows Subsystem for Linux is required)
- boto3 Python library
Ansible minimal file
In this article, we will only scratch the surface of what Ansible can do, but for deploying AWS Cloudformation templates we won’t need more. And if you are not familiar with Ansible, maybe this will encourage you to dive a little deeper and start provisioning EC2 instances with Ansible.
Ansible files are YAML files like Cloudformation templates (even if we can use JSON, YAML is much more easier to read and write).
With a single Ansible file (named Playbook) we will be able to deploy multiple Cloudformation Stacks.
Every Playbook will contain the following lines.
1
2
3
4
5
6
7
---
- hosts: localhost
connection: local
gather_facts: false
tasks:
- <List of tasks>
hostsandconnectionindicate that the playbook will be executed locallygather_facts: falseindicates that we don’t want to gather information about the local machinetaskscan be seen as function calls in a programming language. These function are called Ansible Modules. In the snippet below we are using the Cloudformation module:
1
2
3
4
5
6
7
8
9
10
11
- name: <Name of the Task>
cloudformation:
stack_name: <Name of the Cloudformation stack>
state: present
region: <Region to deploy the stack>
profile: <AWS CLI profile to use>
template: <Path to the Cloudformation template>
tags:
<Cloudformation Stack Tags as Key: Value pairs>
template_parameters:
<Cloudformation Stack Parameters>
A simple example
We will start with the creation of a VPC (example 1).
By convention the Cloudformation templates are named <stack_name>.cfn.yml and the Ansible playbooks
<application>.asb.yml. As this article is not about Cloudformation we will skip the description of all Cloudformation
templates.
To deploy the Cloudformation stack with Ansible we will create the following playbook (example1.asb.yml):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
---
- hosts: localhost
connection: local
gather_facts: false
tasks:
- name: Deploy CloudFormation stack
cloudformation:
stack_name: l-ew1-demo-vpc
state: present
region: eu-west-1
profile: spikeseed-labs
template: vpc.cfn.yml
tags:
Name: l-ew1-demo-vpc-tag
Application: demo
template_parameters:
AccountCode: l
RegionCode: ew1
Application: demo
VpcCidr: 10.68.2.0/23
PublicSubnetCidrAz1: 10.68.2.0/26
PublicSubnetCidrAz2: 10.68.2.64/26
To check what will do the playbook without creating the stack in our AWS account:
1
ansible-playbook example1.asb.yml --check -vvv
To execute the playbook we only have to remove the -check -vvv options:
1
ansible-playbook example1.asb.yml
Once we have seen:
1
localhost : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
Our stack has been successfully deployed in Ireland (eu-west-1) with the name and tags provided:
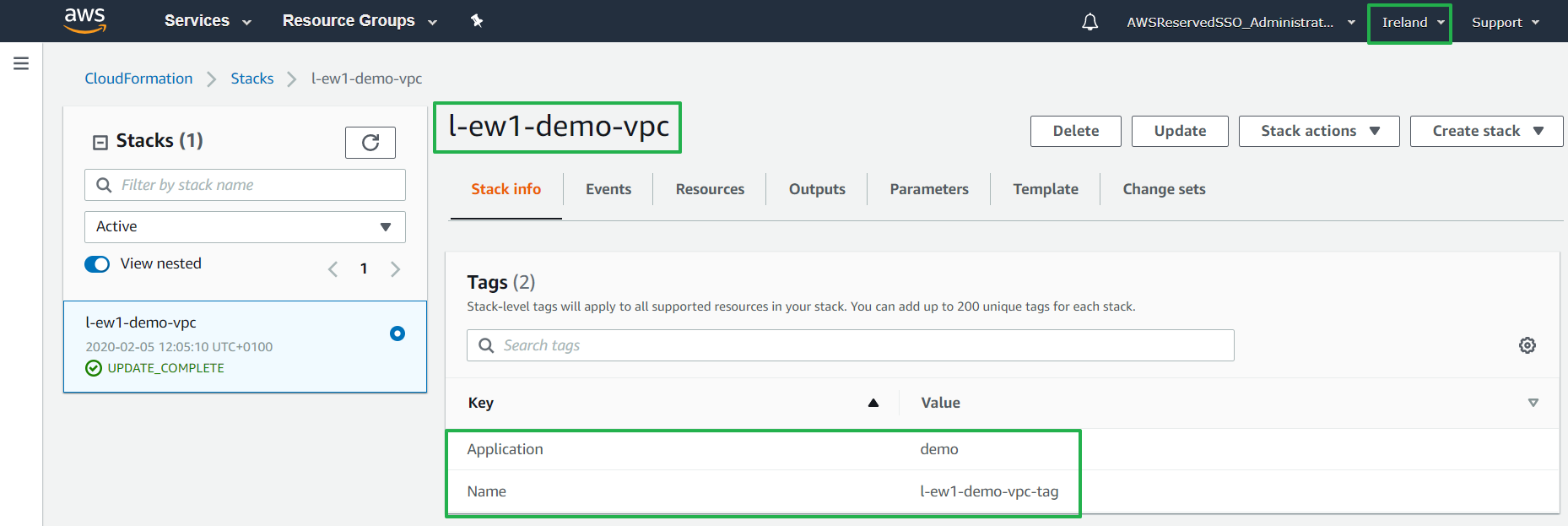
We can then add tags or new resources in the Cloudformation and execute:
1
ansible-playbook example1.asb.yml -check -vvv
to see the changes set.
Variables
Like in any programming (or meta) language we should avoid duplicated code (literals in this case) and use variables.
Variables can have multiple scope:
- A task
- A playbook
- A set of playbooks
Task variables
Let’s define a variable for the name of the stack (local_stack_name). The local_ prefix, help us identify where the
variable is defined and to avoid any conflict with a variable of the same name in another scope (we will discuss about
scope resolution later) (example 2).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- name: 'Deploy CloudFormation stack {{ local_stack_name }}'
cloudformation:
stack_name: "{{ local_stack_name }}"
state: present
region: eu-west-1
profile: spikeseed-labs
template: vpc.cfn.yml
tags:
Name: "{{ local_stack_name }}"
Application: "{{ local_app }}"
template_parameters:
AccountCode: l
RegionCode: ew1
Application: "{{ local_app }}"
VpcCidr: 10.68.2.0/23
PublicSubnetCidrAz1: 10.68.2.0/26
PublicSubnetCidrAz2: 10.68.2.64/26
vars:
local_app: demo
local_stack_name: l-ew1-demo-vpc
To add variables to a task we use the property vars at the task level. Note the indentation, vars is a
property of the task, not of the Cloudformation module.
1
2
3
vars:
local_app: demo
local_stack_name: l-ew1-demo-vpc
We can then use the variable anywhere in the task using the following syntax:
1
"{{ local_stack_name }}"
or using simple quotes
1
'{{ local_stack_name }}'
But contrary to what is shown here for example purpose, we should stay consistent and either use only simple quotes or only double quotes.
If we execute the playbook:
1
ansible-playbook example2.asb.yml --check -vvv
We will see a change as we changed the name of a tag (from l-ew1-demo-vpc-tag to l-ew1-demo-vpc).
We can even add variables inside other variables (example 3)
1
2
3
vars:
local_app: demo
local_stack_name: "l-ew1-{{ local_app }}-vpc"
Playbook variables
Common variables can be extracted and defined at the playbook level, using once again the vars property (example 4):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
---
- hosts: localhost
connection: local
gather_facts: false
vars:
account_name: spikeseed-labs
account_code: l
aws_region: eu-west-1
aws_region_code: ew1
application: demo
tasks:
- name: "Deploy CloudFormation stack {{ local_stack_name }}"
cloudformation:
stack_name: "{{ local_stack_name }}"
state: present
region: "{{ account_name }}"
profile: "{{ aws_region }}"
template: vpc.cfn.yml
tags:
Name: "{{ local_stack_name }}"
Application: "{{ application }}"
template_parameters:
AccountCode: "{{ account_code }}"
RegionCode: "{{ aws_region_code }}"
Application: "{{ application }}"
VpcCidr: 10.68.2.0/23
PublicSubnetCidrAz1: 10.68.2.0/26
PublicSubnetCidrAz2: 10.68.2.64/26
vars:
local_stack_name: "{{ account_code }}-{{ aws_region_code }}-{{ application }}-vpc"
Again if we execute the playbook in check mode, we won’t see any change as we didn’t change anything related to the AWS Cloudformation AWS. We only moved things around in our ansible playbook.
Shared Variables
When we start having multiple playbooks, sharing variables between them is a necessity to avoid duplicating them (example 5).
We first need a new YAML file that we will name common-vars.asb.yml in a folder vars:
1
2
3
4
5
6
---
account_name: spikeseed-labs
account_code: l
aws_region: eu-west-1
aws_region_code: ew1
application: demo
Then we have to import the file into our playbook
1
2
3
4
5
6
7
8
9
10
---
- hosts: localhost
connection: local
gather_facts: false
vars_files:
- vars/common-vars.asb.yml
tasks:
[...]
Variables with complex values
Variables don’t need to be literals, they can be objects or lists that can be used in multiple ways as we will see later (example 6).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
---
aws_regions:
'us-west-1':
code: uw1
[...]
aws_accounts:
'spikeseed-labs':
code: l
environment: sandbox
account_name: spikeseed-labs
account_code: "{{ aws_accounts[account_name].code }}"
aws_region: eu-west-1
aws_region_code: "{{ aws_regions[aws_region].code }}"
application: demo
config:
'spikeseed-labs':
vpc_cidr: 10.68.2.0/23
public_subnet_cidr: 10.68.2.0/24
public_subnet_az1_cidr: 10.68.2.0/26
public_subnet_az2_cidr: 10.68.2.64/26
You may wonder why do we have 2 different objects aws_accounts and config having the key (spikeseed-labs)?
The answer is quite simple: for clear separation of purpose. aws_accounts defines constants linked to our AWS accounts
(we could even add the AWS account ID which can be useful in some cases) that should never changed. config on the other
hand defines the configurations of our infrastructure and the resources in it that may change in the future.
Here we only have CIDR Blocks, but we could have AMI IDs, instance types, ACM certificates ARN, etc.
Now we can change our playbook the following way:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- name: "Deploy CloudFormation stack {{ vpc_stack_name }}"
cloudformation:
stack_name: "{{ vpc_stack_name }}"
state: present
region: "{{ aws_region }}"
profile: "{{ account_name }}"
template: vpc.cfn.yml
tags:
Name: "{{ vpc_stack_name }}"
Application: "{{ application }}"
template_parameters:
AccountCode: "{{ account_code }}"
RegionCode: "{{ aws_region_code }}"
Application: "{{ application }}"
VpcCidr: "{{ config[account_name].vpc_cidr }}"
PublicSubnetCidrAz1: "{{ config[account_name].public_subnet_az1_cidr }}"
PublicSubnetCidrAz2: "{{ config[account_name].public_subnet_az2_cidr }}"
(almost) Everything in our task is a variable.
Execution Variables
It is clear from the previous example that the variables account_name and aws_region could be more dynamic to execute
the playbook and therefore deploy the Cloudformation stack in multiple AWS accounts and/or AWS region (example 7).
First we are going to remove these 2 variables from the file common-vars.asb.yml.
If we execute the playbook, we are going to get an error saying that these variables are undefined. To solve this issue,
we need to add a new option (-e) to our ansible-playbook command:
1
2
3
4
ansible-playbook example7.asb.yml -e '{ \
"account_name": "spikeseed-labs", \
"aws_region": "eu-west-1" \
}' --check -v
The option -e, which stands for “extra variables”, takes a JSON string as parameter. It could be a JSON file as-well
but it will go against the objective to have a single configuration file for everything.
Variables scope resolution
The same variable name can define at all levels:
- task
- playbook
- global
- command line
With Ansible we could define variables in a few other ways, but for the purpose of deploying Cloudformation stacks, these are irrelevant.
To demonstrate the variable scope resolution we will start from scratch using only the debug module (example 8)
vars/common-vars.asb.yml
1
2
3
---
var_1: var 1 - global
var_2: var 2 - global
example8.asb.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
---
- [...]
vars:
var_1: var 1 - playbook
var_2: var 2 - playbook
var_3: var 3 - playbook
vars_files:
- vars/common-vars.asb.yml
tasks:
- debug:
msg: "{{ var_1 }} | {{ var_2 }} | {{ var_3 }}"
vars:
var_1: var 1 - task
var_3: var 3 - task
Then if we execute:
1
ansible-playbook example8.asb.yml
We can see:
1
"msg": "var 1 - task | var 2 - shared | var 3 - task"
And with:
1
2
3
4
5
ansible-playbook example8.asb.yml -e '{ \
"var_1": "var 1 - cli", \
"var_2": "var 2 - cli", \
"var_3": "var 3 - cli" \
}'
The output is:
1
"msg": "var 1 - cli | var 2 - cli | var 3 - cli"
We can conclude that the priority order is:
-e/--extra-varsoption- task variables
- shared variables (
vars_files) - playbook variables
Conditions
Playbooks usually have multiple Cloudformation tasks to create all the resources needed for an application (VPC, ALBs, Cloudfront, Lambdas, EC2s, etc.). These playbooks can then be used to deploy the stacks in multiple environments (AWS Accounts).
With Ansible conditions we deploy a Cloudformation stack much like Cloudformation Conditions with Resources (example 9).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
vars:
a_list: ['dev', 'sandbox']
tasks:
- debug:
msg: "Case 1"
when: var_1 is defined and var_1 == 'active'
- debug:
msg: "Case 2"
when: >-
var_1 is defined and var_2 is defined
and var_1 == 'active' and var_2 == 'active'
- debug:
msg: "Case 3"
when: var_2 is not defined or var_3 is defined
- debug:
msg: "Case 4"
when: var_4 is defined and var_4 in a_list
In this example, we are again using the debug module but this applies to all ansible modules.
Like the vars property, this time we are using the property when at the task level. And you may have noticed that
with when we don’t need quotes or curly braces.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
$ ansible-playbook example9.asb.yml
# Displays:
# "msg": "Case 3"
$ ansible-playbook example9.asb.yml -e \
'{"var_1": "active"}'
# Displays:
# "msg": "Case 1"
# "msg": "Case 3"
$ ansible-playbook example9.asb.yml -e \
'{"var_1": "active", "var_2": "active"}'
# Displays:
# "msg": "Case 1"
# "msg": "Case 2"
$ ansible-playbook example9.asb.yml -e
\ '{"var_2": "active", "var_3": "active"}'
# Displays:
# "msg": "Case 3"
$ ansible-playbook example9.asb.yml -e \
'{"var_2": "active", "var_4": "dev"}'
# Displays:
# "msg": "Case 4"
Loops
Sometimes we want to deploy the same stack in multiple accounts (eg. enabling Cloudtrail) or in multiple accounts and multiple regions (eg. enabling GuardDuty). For this, loops come to the rescue (example 10).
To loop over items we have multiple properties at our disposal (loop, with_items, with_nested, etc.) to be used depending on the type of items to iterate over.
List of strings - JSON like array:
1
2
3
- debug:
msg: "{{ item }}"
loop: [ 0, 2, 4 ]
Output:
1
2
3
4
5
6
7
8
9
ok: [localhost] => (item=0) => {
"msg": 0
}
ok: [localhost] => (item=2) => {
"msg": 2
}
ok: [localhost] => (item=4) => {
"msg": 4
}
The item variable contains the current value.
In Python, it would be:
1
2
for item in [ 0, 2, 4 ]:
print(item)
List of strings - YAML array
1
2
3
4
5
6
- debug:
msg: "{{ item }}"
loop:
- a
- b
- c
Output:
1
2
3
4
5
6
7
8
9
ok: [localhost] => (item=a) => {
"msg": "a"
}
ok: [localhost] => (item=b) => {
"msg": "b"
}
ok: [localhost] => (item=c) => {
"msg": "c"
}
List of objects:
1
2
3
4
5
6
7
- debug:
msg: "{{ item.acc }} | {{ item.acc }}"
loop:
- acc: spikeseed-sandbox
env: sandbox
- acc: spikeseed-prod
env: production
Output:
1
2
3
4
5
6
ok: [localhost] => (item={u'acc': u'spikeseed-sandbox', u'env': u'sandbox'}) => {
"msg": "spikeseed-sandbox | spikeseed-sandbox"
}
ok: [localhost] => (item={u'acc': u'spikeseed-prod', u'env': u'production'}) => {
"msg": "spikeseed-prod | spikeseed-prod"
}
Nested loops:
1
2
3
4
5
- debug:
msg: "{{ item[0] }} | {{ item[1] }}"
with_nested:
- [ x, y, z]
- [ 7, 8, 9]
Output:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
ok: [localhost] => (item=[u'x', 7]) => {
"msg": "x | 7"
}
ok: [localhost] => (item=[u'x', 8]) => {
"msg": "x | 8"
}
ok: [localhost] => (item=[u'x', 9]) => {
"msg": "x | 9"
}
ok: [localhost] => (item=[u'y', 7]) => {
"msg": "y | 7"
}
ok: [localhost] => (item=[u'y', 8]) => {
"msg": "y | 8"
}
ok: [localhost] => (item=[u'y', 9]) => {
"msg": "y | 9"
}
ok: [localhost] => (item=[u'z', 7]) => {
"msg": "z | 7"
}
ok: [localhost] => (item=[u'z', 8]) => {
"msg": "z | 8"
}
ok: [localhost] => (item=[u'z', 9]) => {
"msg": "z | 9"
}
Looping over a dictionary:
1
2
3
4
5
6
7
8
9
- debug:
msg: "{{ item.key }} | {{ item.value.code }}"
loop: "{{ aws_regions|dict2items }}"
vars:
aws_regions:
'ca-central-1':
code: cc1
'eu-central-1':
code: ec1
Output:
1
2
3
4
5
6
ok: [localhost] => (item={'key': 'ca-central-1', 'value': {'code': 'cc1'}}) => {
"msg": "ca-central-1 | cc1"
}
ok: [localhost] => (item={'key': 'eu-central-1', 'value': {'code': 'ec1'}}) => {
"msg": "eu-central-1 | ec1"
}
Sharing AWS Resources between stacks
We usually split stacks by component (Buckets, VPC/Subnets, WAF/Cloudfront, Bastion, Reverse Proxy, Application with ALB, etc) and therefore we need to share resource IDs/ARNs between stacks. Multiple options are at our disposal:
- Cloudformation Export/Import values (usually used with Nested stacks)
- Cloudformation Outputs
- Cloudformation Stacks Resources
- SSM Parameters
We won’t discuss Export/Import values further as Ansible can achieve the same results with Outputs.
Ansible Facts
With the Ansible module cloudformation_info we can retrieve details about previously deployed stacks (example 11).
First we are going to add Outputs to vpc.cfn.yml:
1
2
3
4
Outputs:
DefaultSecurityGroupId:
Value: !GetAtt Vpc.DefaultSecurityGroup
Then in example11.asb.yml we can use the cloudformation_info and set_fact modules, to retrieve and store information about our stack:
1
2
3
4
5
6
7
8
9
10
11
12
- name: "Get facts on {{ vpc_stack_name }}"
check_mode: no
cloudformation_facts:
stack_name: "{{ vpc_stack_name }}"
region: "{{ aws_region }}"
profile: "{{ account_name }}"
stack_resources: yes
failed_when: cloudformation[vpc_stack_name] is undefined
- name: "Set fact for {{ vpc_stack_name }}"
set_fact:
vpc_stack: "{{ cloudformation[vpc_stack_name] }}"
And finally, using the debug module, we can display the content of the variable vpc_stack:
1
2
3
4
5
6
7
8
- debug:
msg: "Stack: {{ vpc_stack }}"
- debug:
msg: "Stack Resources: {{ vpc_stack.stack_resources }}"
- debug:
msg: "Stack Outputs: {{ vpc_stack.stack_outputs }}"
In practice, we would use stack_resources and stack_outputs to retrieve created resources and pass them to other Cloudformation stack:
1
2
3
4
5
6
7
8
9
10
11
12
13
- debug:
msg: "VPC ID: {{ vpc_stack.stack_resources.Vpc }}"
- debug:
msg: >-
PublicSubnets:
{{ vpc_stack.stack_resources.PublicSubnetAz1 }},
{{ vpc_stack.stack_resources.PublicSubnetAz2 }}
- debug:
msg: >-
DefaultSecurityGroupId:
{{ vpc_stack.stack_outputs.DefaultSecurityGroupId }}
Output:
1
2
3
"msg": "VPC ID: vpc-02c67f5b0708338aa"
"msg": "PublicSubnets: subnet-07aa79f9fe43f2ec3, subnet-0f0b669850bd4edc8"
"msg": "DefaultSecurityGroupId: sg-01d83cc80e404a7d3"
Working with stack_resources and stack_outputs is nice and easy, but tedious as it requires:
- 10 of lines of code to get a single stack
- knowing the exact name of the stack (not always easy when working with dozen of playbooks)
- knowing the
Resourcename orOutputvalue you want to retrieve.
We could think of adding the stack name to our common-vars file but:
- it will clutter the file if you have hundred of stacks
- it won’t be always possible when deploying stacks cross-account/cross-region
SSM Parameters
Another solution, not directly related to Ansible but which can be improved with it, is to store everything in AWS SSM Parameter Store (example 12).
Cloudformation features will help us with this:
- AWS::SSM::Parameter
- Cloudformation SSM Parameter Types
First we are going to add the name of the SSM parameter store keys in our common-vars.asb.yml file:
1
2
ssm_vpc_id_key: /cfn/vpc/id
ssm_public_subnets_id_key: /cfn/publicSubnets/ids
These variables can then be used in a playbook as usual:
1
2
SsmVpcIdKey: "{{ ssm_vpc_id_key }}"
SsmPublicSubnetIdsKey: "{{ ssm_public_subnets_id_key }}"
Then, we can store the VPC ID and Subnet IDs created in the VPC stack (vpc.cfn.yml):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
Parameters:
[...]
SsmVpcIdKey:
Type: String
SsmPublicSubnetIdsKey:
Type: String
Resources:
[...]
SsmVpcId:
Type: AWS::SSM::Parameter
Properties:
Name: !Ref SsmVpcIdKey
Type: String
Value: !Ref Vpc
SsmPublicSubnetIds:
Type: AWS::SSM::Parameter
Properties:
Name: !Ref SsmPublicSubnetIdsKey
Type: String
Value: !Join [ ',', [ !Ref PublicSubnetAz1, !Ref PublicSubnetAz2 ] ]
To retrieve the values stored, we can use aws_ssm lookup plugin in the playbook (example12.asb.yml).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
- name: Get values from SSM
set_fact:
ssm_vpc_id: "{{ lookup( 'aws_ssm', ssm_vpc_id_key, region=aws_region, aws_profile=account_name ) }}"
ssm_public_subnets_id: "{{ lookup( 'aws_ssm', ssm_public_subnets_id_key, region=aws_region, aws_profile=account_name ) }}"
ssm_non_existent: "{{ lookup( 'aws_ssm', '/non/existent', region=aws_region, aws_profile=account_name ) }}"
- debug:
msg: >-
ssm_vpc_id: {{ ssm_vpc_id }}
| ssm_public_subnets_id: {{ ssm_public_subnets_id }}
| ssm_non_existent: <{{ ssm_non_existent }}>
# Displays:
# "msg": "ssm_vpc_id: vpc-02c67f5b0708338aa | ssm_public_subnets_id: subnet-07aa79f9fe43f2ec3,subnet-0f0b669850bd4edc8 | ssm_non_existent: <>"
ssm_non_existent has been added to demonstrate that if a key doesn’t exist, the execution of the playbook doesn’t fail,
contrary to the AWS CLI aws ssm get-parameter [...].
Of course, we would use aws_ssm lookup plugin only if we need the value of a SSM Parameter outside
a Cloudformation template or if the parameter is in another AWS Region or AWS Account.
Otherwise, we would use the parameter type: AWS::SSM::Parameter::Value<String>, as demonstrated below (securitygroups.cfn.yml).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Parameters:
[...]
SsmVpcIdKey:
Description: SSM Key storing the value of the VPC ID
Type : AWS::SSM::Parameter::Value<String>
Resources:
SecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupName: name-sg
GroupDescription: description sg
VpcId: !Ref SsmVpcIdKey # resolved
Tags:
- Key: Name
Value: name-sg
The upside of this design is that we can use variables with SSM Parameter key as values. We are not relying on Resource name or any literal value. The downside is that we have to create all needed entries in AWS SSM Parameter Store.
Conclusion
As you’ve seen throughout this article, Ansible can help us a lot to ease the deployment of Cloudformation Stacks. And once you’ve tried it, you won’t be able to work without it. Furthermore, Ansible has a lot of other “AWS modules”.