
Pierre Renard
Cloud technologies addict. Pierre enjoys making awesome cloud-based solutions.
Query structured data easily with Amazon Athena
Nowadays, in this fast-moving world, SaaS solutions become the new standard. Because of that, it’s more and more important to monitor your SaaS solution to avoid a potential outage.
This blog post focuses and shows how Amazon Athena can help you for troubleshooting or monitoring purposes. We will see how this service can be used to easily parse and query your load balancer logs. Let’s deep dive into the subject
What’s Amazon Athena
Amazon Athena is a service which lets you query your data stored in Amazon S3 using SQL queries. It can analyze unstructured or structured data like CSV or JSON. Most of the time, queries results are within seconds but for large amount of data it can take up to several minutes. For this service, you only pay per TB of data scanned. For more information about the pricing, refer to Athena pricing.
To illustrate the power of Amazon Athena, we will run queries against JSON structured data stored in our AWS S3 bucket.
Architecture
The following diagram depicts how we use Amazon Athena to query logs from a load balancer.
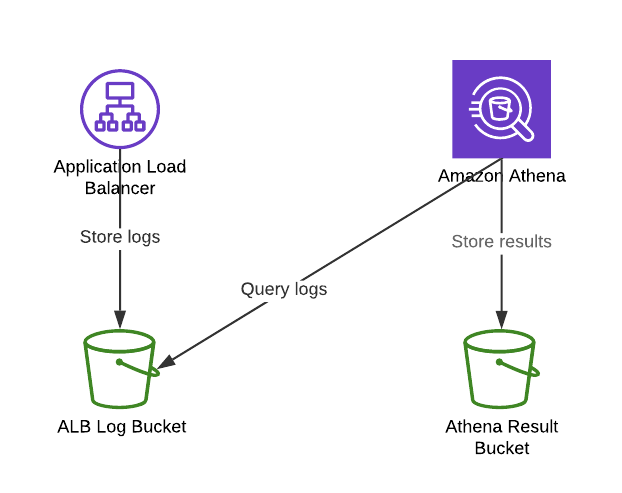
- First, The load balancer delivers logs to the bucket. The load balancer must have the property
Access logschecked and the bucket must have the correct policy to allow log delivery. For more information refer to Enable Access Logs for Your Load Balancer. - Then, We must create a
tableand aschemain order to query our logs with SQL queries - Results are stored in a pre-defined S3 bucket (
s3://aws-athena-query-results-${ACCOUNTID}-${AWS_REGION}/) in a CSV file.
Amazon Athena setup
For our usage, we will create:
- A database
- A schema in our database
- A partition
Then, we will query our logs with a SQL query.
Let’s create the database first.
Create the database
First, you have to create a database which will contain our tables. This Query will create a database named logs.
1
CREATE DATABASE IF NOT EXISTS logs;
Create the schema
Once done with the database creation, let’s create our table named alb_logs with the following SQL query, replace parameters in the query and execute:
ALB_LOG_BUCKET: the bucket name where your load balancer logs are stored,AWS_ACCOUNT_ID: the AWS account ID where your bucket is located,AWS_REGION: The AWS region where your bucket is located
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
CREATE EXTERNAL TABLE IF NOT EXISTS alb_logs (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code string,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string
)
PARTITIONED BY(year string, month string, day string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1', 'input.regex' = '([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\"($| \"[^ ]*\")(.*)') LOCATION 's3://${ALB_LOG_BUCKET}/AWSLogs/${AWS_ACCOUNT_ID}/elasticloadbalancing/${AWS_REGION}/';
Do I have to partition my data?
For sure, you can create your database without partitioning your log datas. But the more logs you have, the more time it will consume to run the query. Then, I decided to partition my table by year, month and day.
1
2
3
...
PARTITIONED BY(year string, month string, day string)
...
Queries are faster because I run the query only against one partition of my logs and not of the entire logs. The counterpart is that I have to create a partition for every day. Hopefully, it can be automated with Lambdas!
Create a partition
The query bellow creates a partition for a given day, month and year.
1
ALTER TABLE alb_logs ADD PARTITION (year='2020',month='03',day='12') location 's3://${ALB_LOG_BUCKET}/AWSLogs/${AWS_ACCOUNT_ID}/elasticloadbalancing/${AWS_REGION}/2020/03/12';
Query logs
Once all the previous setup is done, you are good to run queries. For example, the query bellow gathers the top 10 of requests with HTTP status code of 4xx.
1
2
3
4
5
6
7
8
9
SELECT count(request_url) as counter, request_verb, request_url, target_status_code, user_agent
FROM logs.alb_logs
WHERE ( year = '2020'
AND month = '03'
AND day = '12' )
AND target_status_code like '%4%%'
GROUP BY request_url, request_verb, target_status_code, user_agent
ORDER BY counter DESC
LIMIT 10;
Here is what result looks like for the given date:

One step further, automation with lambdas!
In fact, we like to automate everything and this process can be pushed one step further by running queries automatically. The following solution describes how we can automate the process to get a report everyday which can be downloaded when needed.
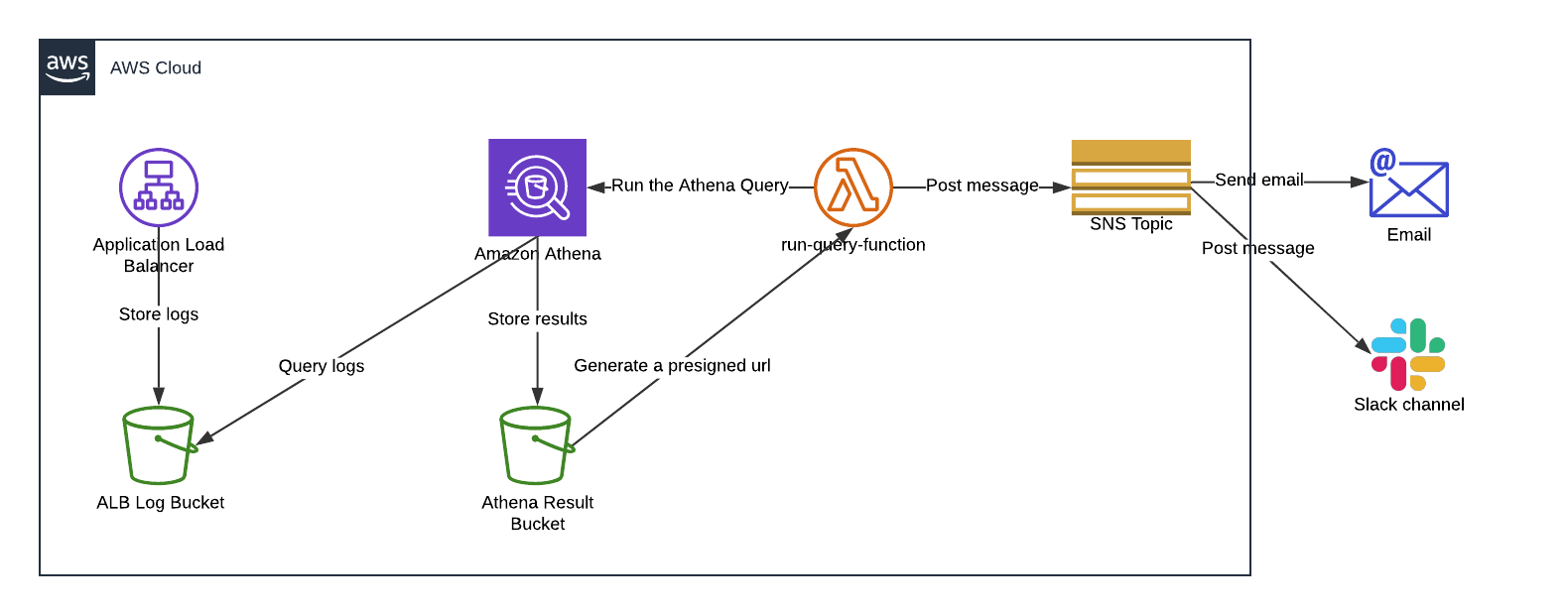
The run-query-function lambda is triggered everyday with a CloudWatch event. The lambda runs queries in Amazon Athena. Then, results are stored in an S3 bucket in a CSV format. The lambda generates a presigned URL that is valid for a short period of time and posts it to an SNS topic. Finally, the SNS topic forwards the message to subscribers. In our case it’s either a distribution list or a slack private channel.
Conclusion
To conclude, Amazon Athena is a key enabler for querying structured data stored in S3. The same pattern can be applied for logs like VPC flow logs or other data formats.
Finally, AWS RE:Invent videos are always a great start to discover the features of a new service. I recommend this one for deep diving into Amazon Athena.